Top 10 Fastest AI Voice Generators In The World 2026


Table of Contents
The demand for instant, natural-sounding synthetic speech has never been higher. From live streaming and conversational AI agents to automated customer service and rapid content production, the speed of text-to-speech (TTS) generation is now a critical competitive factor. To build this ranking, we weighed criteria including raw generation speed (measured in milliseconds of latency), output quality (naturalness, emotional range, and clarity), cost efficiency (per-character or per-credit pricing), and suitability for real-time applications. We consulted independent leaderboards such as the Artificial Analysis Speech Arena and HuggingFace TTS Arena, alongside API pricing guides and expert analyses from 2026. The result is a list of ten platforms that represent the state of the art in rapid voice synthesis.
The List Of The Top 10 Fastest AI Voice Generators 2026:
1. MiniMax Speech 2.6 Turbo

MiniMax Speech 2.6 Turbo sits at the top of our list because it prioritizes speed above all else without completely sacrificing output quality. It achieves an end-to-end latency of under 250 milliseconds, making it ideal for developers who need near-instant voice output in real-time applications. The model supports more than 40 languages and offers hundreds of built-in voices. At just 6 credits per use, it also delivers exceptional value. The Turbo variant intentionally trades a small amount of audio fidelity compared to its HD counterpart in exchange for significantly faster generation and lower computational cost. This makes it the go-to choice for rapid content production pipelines and interactive chatbots where every millisecond counts.
2. ElevenLabs TTS Turbo v2.5

ElevenLabs has long been the benchmark for voice realism, and the TTS Turbo v2.5 model proves that speed does not have to come at the expense of quality. This version delivers sub-300-millisecond response times, enabling seamless streaming for conversational AI and interactive content. It retains ElevenLabs' signature natural breathing patterns and emotional inflection, even at high speeds. Priced at $0.05 per 1,000 characters on the fal.ai API, it sits at a premium level but is designed for teams that require human-grade voice quality in quick-turnaround projects. For applications where both speed and voice realism are non-negotiable, this model remains a top contender.
3. VibeVoice 0.5B

VibeVoice 0.5B earns its place as the best value option in the top three. It delivers exceptional quality relative to its price, with fast generation speeds and multiple natural voices available at just 6 credits per use. The model's lightweight architecture enables rapid inference without requiring expensive hardware, making it accessible to independent creators and small studios. It achieves high-speed text-to-speech conversion while maintaining natural-sounding audio output, striking a balance that many competitors struggle to match at this price point. For creators who need reliable results without premium pricing, VibeVoice is a standout choice.
4. Index TTS 2.0

Index TTS 2.0 is not the absolute fastest generator on this list, but it holds the distinction of being the overall top-ranked AI voice generator in 2026 according to JAI Portal's comprehensive evaluation. It earns a perfect 5/5 score for quality, offering lifelike, emotionally expressive speech with advanced voice cloning and emotion control capabilities. At 15 credits per use and a speed score of 4/5, it is designed for professional voiceover work and demanding production environments where fidelity matters more than raw speed. The platform excels at balancing generation speed with the highest possible output fidelity, making it the preferred tool for studios and agencies.
5. Maya Stream
Maya Stream is specifically optimized for real-time streaming applications, and it achieves the rare feat of scoring a perfect 5/5 in both speed and quality simultaneously. It is engineered for live content creators who need immediate voice generation without latency issues during broadcasts or interactive sessions. The platform maintains broadcast-quality audio output even under continuous streaming conditions, a technical challenge that many competitors have not fully solved. At 15 credits per use, it represents a premium option for professionals who cannot tolerate any delay in their voice generation pipeline.
6. Fish Audio API (S2 Model)
Fish Audio's S2 model disrupts the market with a compelling combination of speed and cost efficiency. It delivers streaming response times under 300 milliseconds, fast enough for real-time conversational AI and interactive content. The flat-rate pricing structure of approximately $15 per million characters simplifies budgeting compared to credit-based systems, and it represents a dramatic cost advantage over competitors like ElevenLabs, which charges roughly $165 per million characters. The S2 model is built on the open-weights SGLang inference engine, allowing developers to self-host for full control over their infrastructure. Voice cloning requires only 15 seconds of sample audio, and the platform boasts a library of over 2 million voices. For teams scaling voice features to millions of users, this pricing alone is transformative.
7. Cartesia Sonic 3.5 Turbo
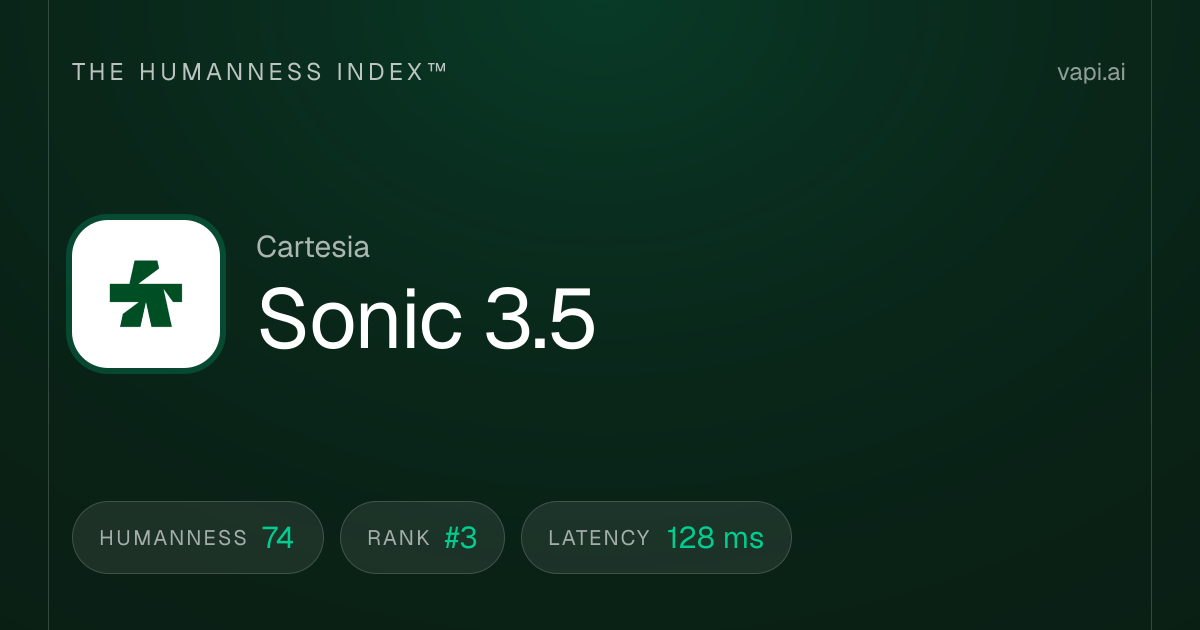
Cartesia Sonic 3.5 Turbo is the absolute fastest model on this list by one critical metric: time-to-first-byte. It achieves approximately 40 milliseconds of latency using State Space Models (SSMs) instead of the transformers used by most competitors. This sub-50-millisecond response time makes a perceptible difference in latency-critical applications such as telephony systems, live customer service agents, and interactive experiences where even 200 milliseconds versus 40 milliseconds feels sluggish. The company raised $100 million in funding led by Kleiner Perkins, Index Ventures, Lightspeed, and NVIDIA specifically to optimize for these use cases. On the Artificial Analysis Speech Arena, it holds an ELO score of approximately 1,204. For developers building real-time voice interfaces where every millisecond matters, Cartesia is the clear leader.
8. Inworld Realtime TTS-2

Inworld Realtime TTS-2 Research Preview is the top-ranked real-time TTS model on independent leaderboards. It leads both the Artificial Analysis Realtime TTS Arena with an ELO of approximately 1,208 and the HuggingFace TTS Arena with an ELO of 1,578. These independent rankings carry significant weight because they are based on blind listening tests rather than vendor claims. The model demonstrated a 40% cost reduction and a 4% lift in user retention during A/B testing with Talkpal AI across more than 5 million users. In a separate case study, Bible Chat scaled AI voice features to millions of users while reducing costs by over 90% compared to their previous TTS provider. For organizations that prioritize verified performance over marketing claims, Inworld's model offers proven results at scale.
9. Kokoro TTS

Kokoro TTS offers the fastest generation speed among budget-friendly options, priced at just $0.02 per 1,000 characters on the fal.ai platform. This makes it the ideal choice for teams that need rapid voice generation at the lowest possible per-character cost. Despite its low price point, it delivers solid quality output suitable for production environments where cost efficiency is the primary concern. The model is particularly well-suited for high-volume applications such as automated narration, accessibility tools, and content localization, where speed and affordability outweigh the need for absolute voice quality. For startups and cost-conscious teams, Kokoro provides a remarkably fast and functional entry point into AI voice generation.
10. Maya1 TTS

Maya1 TTS rounds out our top ten by achieving strong generation speeds while specializing in emotional voice delivery. It earns a perfect 5/5 quality score and a 4/5 speed score, priced at 15 credits per use. The platform is designed for projects that require nuanced emotional expression in the voice output, such as audiobook narration, character dialogue, and emotionally aware virtual assistants. It balances rapid generation with sophisticated emotional modeling capabilities that many faster tools lack. For creators who need both speed and the ability to convey subtle emotional shifts, Maya1 offers a specialized solution that fills a distinct niche in the market.
The landscape of AI voice generation in 2026 is defined by a clear trade-off between raw speed and output quality, but the gap is narrowing rapidly. Models like MiniMax Speech 2.6 Turbo and Cartesia Sonic 3.5 Turbo are pushing the boundaries of what is possible at sub-50-millisecond latency, while platforms like Index TTS 2.0 and Inworld Realtime TTS-2 prove that high fidelity and strong speed can coexist. The most significant trend, however, is the dramatic reduction in cost. Fish Audio's S2 model at $15 per million characters and Kokoro TTS at $0.02 per 1,000 characters are making fast, high-quality voice generation accessible to teams that would have been priced out just a year ago. As these technologies continue to mature, the line between synthetic and human speech will become increasingly difficult to distinguish, and speed will remain the decisive factor for real-time applications.
Related Posts




1 Comment
Join the discussion and share your thoughts