दुनिया के शीर्ष 10 सबसे तेज़ AI वॉइस जनरेटर 2026


Table of Contents
तत्काल, प्राकृतिक-ध्वनि वाले सिंथेटिक भाषण की मांग पहले कभी इतनी अधिक नहीं रही। लाइव स्ट्रीमिंग और संवादी AI एजेंटों से लेकर स्वचालित ग्राहक सेवा और तीव्र सामग्री उत्पादन तक, टेक्स्ट-टू-स्पीच (TTS) जनरेशन की गति अब एक महत्वपूर्ण प्रतिस्पर्धात्मक कारक है। इस रैंकिंग को बनाने के लिए, हमने कच्ची जनरेशन गति (मिलीसेकंड में विलंबता), आउटपुट गुणवत्ता (स्वाभाविकता, भावनात्मक सीमा और स्पष्टता), लागत दक्षता (प्रति-अक्षर या प्रति-क्रेडिट मूल्य निर्धारण), और रीयल-टाइम अनुप्रयोगों के लिए उपयुक्तता जैसे मानदंडों का मूल्यांकन किया। हमने Artificial Analysis Speech Arena और HuggingFace TTS Arena जैसे स्वतंत्र लीडरबोर्ड के साथ-साथ 2026 के API मूल्य निर्धारण गाइड और विशेषज्ञ विश्लेषणों से परामर्श किया। परिणाम दस प्लेटफार्मों की एक सूची है जो तीव्र वॉयस सिंथेसिस में अत्याधुनिक तकनीक का प्रतिनिधित्व करते हैं।
2026 के शीर्ष 10 सबसे तेज़ AI वॉयस जनरेटर की सूची:
1. MiniMax Speech 2.6 Turbo

MiniMax Speech 2.6 Turbo हमारी सूची में शीर्ष पर है क्योंकि यह आउटपुट गुणवत्ता को पूरी तरह से बलिदान किए बिना गति को सबसे ऊपर प्राथमिकता देता है। यह 250 मिलीसेकंड से कम की एंड-टू-एंड विलंबता प्राप्त करता है, जो इसे डेवलपर्स के लिए आदर्श बनाता है जिन्हें रीयल-टाइम अनुप्रयोगों में लगभग-तत्काल वॉयस आउटपुट की आवश्यकता होती है। यह मॉडल 40 से अधिक भाषाओं का समर्थन करता है और सैकड़ों अंतर्निहित आवाज़ें प्रदान करता है। प्रति उपयोग केवल 6 क्रेडिट पर, यह असाधारण मूल्य भी प्रदान करता है। Turbo वेरिएंट जानबूझकर अपने HD समकक्ष की तुलना में थोड़ी मात्रा में ऑडियो निष्ठा का व्यापार करता है, बदले में काफी तेज़ जनरेशन और कम कम्प्यूटेशनल लागत प्रदान करता है। यह इसे तीव्र सामग्री उत्पादन पाइपलाइनों और इंटरैक्टिव चैटबॉट के लिए पसंदीदा विकल्प बनाता है जहां हर मिलीसेकंड मायने रखता है।
2. ElevenLabs TTS Turbo v2.5

ElevenLabs लंबे समय से वॉयस यथार्थवाद के लिए बेंचमार्क रहा है, और TTS Turbo v2.5 मॉडल साबित करता है कि गति को गुणवत्ता की कीमत पर नहीं आना चाहिए। यह संस्करण 300 मिलीसेकंड से कम की प्रतिक्रिया समय प्रदान करता है, जो संवादी AI और इंटरैक्टिव सामग्री के लिए निर्बाध स्ट्रीमिंग सक्षम करता है। यह उच्च गति पर भी ElevenLabs के हस्ताक्षर प्राकृतिक श्वास पैटर्न और भावनात्मक विभक्ति को बरकरार रखता है। fal.ai API पर प्रति 1,000 अक्षरों पर $0.05 की कीमत पर, यह एक प्रीमियम स्तर पर है, लेकिन उन टीमों के लिए डिज़ाइन किया गया है जिन्हें त्वरित-टर्नअराउंड परियोजनाओं में मानव-ग्रेड वॉयस गुणवत्ता की आवश्यकता होती है। उन अनुप्रयोगों के लिए जहां गति और वॉयस यथार्थवाद दोनों अपरिहार्य हैं, यह मॉडल शीर्ष दावेदार बना हुआ है।
3. VibeVoice 0.5B

VibeVoice 0.5B शीर्ष तीन में सर्वोत्तम मूल्य विकल्प के रूप में अपना स्थान अर्जित करता है। यह अपनी कीमत के सापेक्ष असाधारण गुणवत्ता प्रदान करता है, तेज़ जनरेशन गति और प्रति उपयोग केवल 6 क्रेडिट पर कई प्राकृतिक आवाज़ों के साथ। मॉडल की हल्की आर्किटेक्चर महंगे हार्डवेयर की आवश्यकता के बिना तीव्र अनुमान को सक्षम बनाती है, जो इसे स्वतंत्र रचनाकारों और छोटे स्टूडियो के लिए सुलभ बनाती है। यह प्राकृतिक-ध्वनि वाले ऑडियो आउटपुट को बनाए रखते हुए उच्च गति वाले टेक्स्ट-टू-स्पीच रूपांतरण प्राप्त करता है, एक ऐसा संतुलन बनाता है जिसे कई प्रतियोगी इस मूल्य बिंदु पर मिलान करने में संघर्ष करते हैं। उन रचनाकारों के लिए जिन्हें प्रीमियम मूल्य निर्धारण के बिना विश्वसनीय परिणामों की आवश्यकता है, VibeVoice एक उत्कृष्ट विकल्प है।
4. Index TTS 2.0

Index TTS 2.0 इस सूची में सबसे तेज़ जनरेटर नहीं है, लेकिन JAI Portal के व्यापक मूल्यांकन के अनुसार 2026 में समग्र रूप से शीर्ष रैंक वाले AI वॉयस जनरेटर होने का गौरव प्राप्त है। यह गुणवत्ता के लिए पूर्ण 5/5 स्कोर अर्जित करता है, जो उन्नत वॉयस क्लोनिंग और भावना नियंत्रण क्षमताओं के साथ जीवंत, भावनात्मक रूप से अभिव्यंजक भाषण प्रदान करता है। प्रति उपयोग 15 क्रेडिट और 4/5 के गति स्कोर पर, यह पेशेवर वॉयसओवर कार्य और मांग वाले उत्पादन वातावरण के लिए डिज़ाइन किया गया है जहां कच्ची गति की तुलना में निष्ठा अधिक मायने रखती है। प्लेटफ़ॉर्म उच्चतम संभव आउटपुट निष्ठा के साथ जनरेशन गति को संतुलित करने में उत्कृष्ट है, जो इसे स्टूडियो और एजेंसियों के लिए पसंदीदा उपकरण बनाता है।
5. Maya Stream
Maya Stream विशेष रूप से रीयल-टाइम स्ट्रीमिंग अनुप्रयोगों के लिए अनुकूलित है, और यह एक साथ गति और गुणवत्ता दोनों में पूर्ण 5/5 स्कोर करने की दुर्लभ उपलब्धि प्राप्त करता है। यह लाइव सामग्री निर्माताओं के लिए इंजीनियर किया गया है जिन्हें प्रसारण या इंटरैक्टिव सत्रों के दौरान विलंबता मुद्दों के बिना तत्काल वॉयस जनरेशन की आवश्यकता होती है। प्लेटफ़ॉर्म निरंतर स्ट्रीमिंग स्थितियों के तहत भी प्रसारण-गुणवत्ता वाले ऑडियो आउटपुट बनाए रखता है, एक तकनीकी चुनौती जिसे कई प्रतियोगियों ने पूरी तरह से हल नहीं किया है। प्रति उपयोग 15 क्रेडिट पर, यह उन पेशेवरों के लिए एक प्रीमियम विकल्प का प्रतिनिधित्व करता है जो अपने वॉयस जनरेशन पाइपलाइन में किसी भी देरी को बर्दाश्त नहीं कर सकते।
6. Fish Audio API (S2 Model)
Fish Audio का S2 मॉडल गति और लागत दक्षता के एक सम्मोहक संयोजन के साथ बाजार में हलचल मचाता है। यह 300 मिलीसेकंड से कम की स्ट्रीमिंग प्रतिक्रिया समय प्रदान करता है, जो रीयल-टाइम संवादी AI और इंटरैक्टिव सामग्री के लिए पर्याप्त तेज़ है। लगभग $15 प्रति मिलियन अक्षरों की फ्लैट-रेट मूल्य निर्धारण संरचना क्रेडिट-आधारित सिस्टम की तुलना में बजट को सरल बनाती है, और यह ElevenLabs जैसे प्रतिस्पर्धियों पर एक नाटकीय लागत लाभ का प्रतिनिधित्व करता है, जो लगभग $165 प्रति मिलियन अक्षरों का शुल्क लेता है। S2 मॉडल ओपन-वेट SGLang इंफ़रेंस इंजन पर बनाया गया है, जो डेवलपर्स को अपने बुनियादी ढांचे पर पूर्ण नियंत्रण के लिए सेल्फ-होस्ट करने की अनुमति देता है। वॉयस क्लोनिंग के लिए केवल 15 सेकंड के नमूना ऑडियो की आवश्यकता होती है, और प्लेटफ़ॉर्म में 2 मिलियन से अधिक आवाज़ों की लाइब्रेरी है। लाखों उपयोगकर्ताओं के लिए वॉयस सुविधाओं को स्केल करने वाली टीमों के लिए, यह मूल्य निर्धारण अकेले परिवर्तनकारी है।
7. Cartesia Sonic 3.5 Turbo
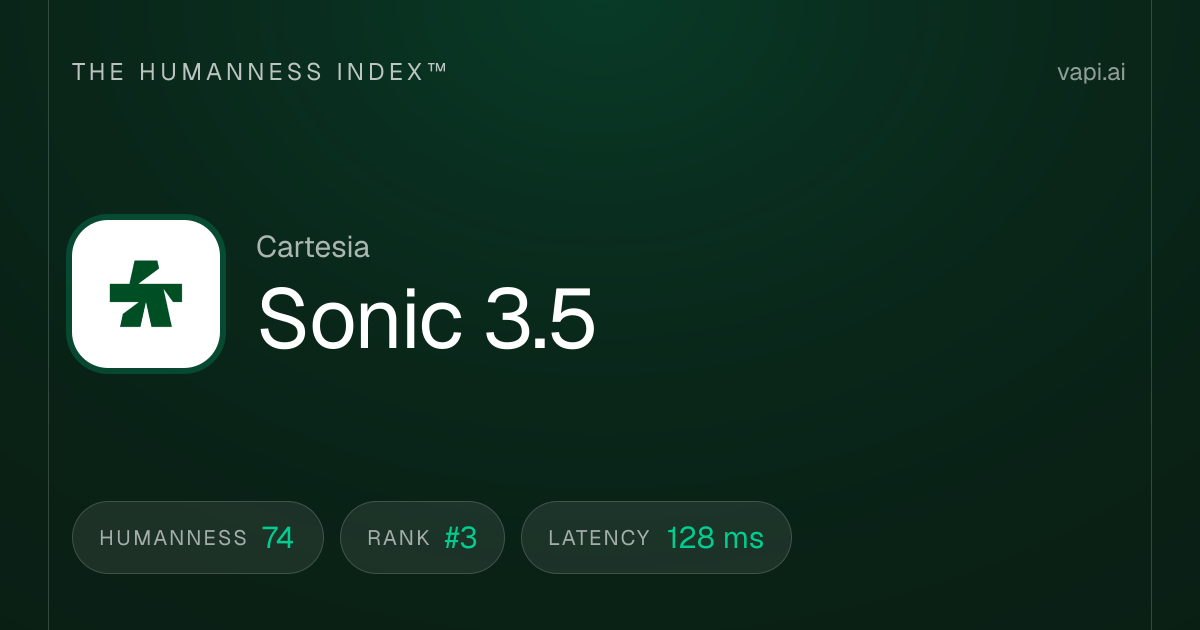
Cartesia Sonic 3.5 Turbo एक महत्वपूर्ण मीट्रिक द्वारा इस सूची में सबसे तेज़ मॉडल है: टाइम-टू-फर्स्ट-बाइट। यह अधिकांश प्रतिस्पर्धियों द्वारा उपयोग किए जाने वाले ट्रांसफॉर्मर के बजाय स्टेट स्पेस मॉडल (SSMs) का उपयोग करके लगभग 40 मिलीसेकंड की विलंबता प्राप्त करता है। यह 50 मिलीसेकंड से कम का प्रतिक्रिया समय विलंबता-महत्वपूर्ण अनुप्रयोगों जैसे टेलीफोनी सिस्टम, लाइव ग्राहक सेवा एजेंट और इंटरैक्टिव अनुभवों में एक बोधगम्य अंतर बनाता है, जहां 200 मिलीसेकंड बनाम 40 मिलीसेकंड भी सुस्त लगता है। कंपनी ने विशेष रूप से इन उपयोग मामलों के लिए अनुकूलन करने के लिए Kleiner Perkins, Index Ventures, Lightspeed और NVIDIA के नेतृत्व में $100 मिलियन का फंडिंग जुटाया। Artificial Analysis Speech Arena पर, इसका ELO स्कोर लगभग 1,204 है। रीयल-टाइम वॉयस इंटरफेस बनाने वाले डेवलपर्स के लिए जहां हर मिलीसेकंड मायने रखता है, Cartesia स्पष्ट नेता है।
8. Inworld Realtime TTS-2

Inworld Realtime TTS-2 Research Preview स्वतंत्र लीडरबोर्ड पर शीर्ष रैंक वाला रीयल-टाइम TTS मॉडल है। यह Artificial Analysis Realtime TTS Arena में लगभग 1,208 के ELO और HuggingFace TTS Arena में 1,578 के ELO के साथ अग्रणी है। ये स्वतंत्र रैंकिंग महत्वपूर्ण वजन रखती हैं क्योंकि वे विक्रेता के दावों के बजाय ब्लाइंड सुनने के परीक्षणों पर आधारित हैं। मॉडल ने Talkpal AI के साथ 5 मिलियन से अधिक उपयोगकर्ताओं पर A/B परीक्षण के दौरान 40% लागत में कमी और उपयोगकर्ता प्रतिधारण में 4% की वृद्धि प्रदर्शित की। एक अलग केस स्टडी में, Bible Chat ने अपने पिछले TTS प्रदाता की तुलना में लागत में 90% से अधिक की कमी करते हुए लाखों उपयोगकर्ताओं के लिए AI वॉयस सुविधाओं को स्केल किया। उन संगठनों के लिए जो मार्केटिंग के दावों पर सत्यापित प्रदर्शन को प्राथमिकता देते हैं, Inworld का मॉडल पैमाने पर सिद्ध परिणाम प्रदान करता है।
9. Kokoro TTS

Kokoro TTS बजट-अनुकूल विकल्पों में सबसे तेज़ जनरेशन गति प्रदान करता है, fal.ai प्लेटफ़ॉर्म पर प्रति 1,000 अक्षरों पर केवल $0.02 की कीमत पर। यह इसे उन टीमों के लिए आदर्श विकल्प बनाता है जिन्हें सबसे कम संभव प्रति-अक्षर लागत पर तीव्र वॉयस जनरेशन की आवश्यकता होती है। अपने कम मूल्य बिंदु के बावजूद, यह उत्पादन वातावरण के लिए उपयुक्त ठोस गुणवत्ता वाला आउटपुट प्रदान करता है जहां लागत दक्षता प्राथमिक चिंता है। मॉडल विशेष रूप से उच्च-मात्रा वाले अनुप्रयोगों जैसे स्वचालित कथन, पहुंच उपकरण और सामग्री स्थानीयकरण के लिए उपयुक्त है, जहां गति और सामर्थ्य पूर्ण वॉयस गुणवत्ता की आवश्यकता से अधिक महत्वपूर्ण हैं। स्टार्टअप और लागत-सचेत टीमों के लिए, Kokoro AI वॉयस जनरेशन में एक उल्लेखनीय रूप से तेज़ और कार्यात्मक प्रवेश बिंदु प्रदान करता है।
10. Maya1 TTS

Maya1 TTS भावनात्मक वॉयस डिलीवरी में विशेषज्ञता रखते हुए मजबूत जनरेशन गति प्राप्त करके हमारे शीर्ष दस को पूरा करता है। यह प्रति उपयोग 15 क्रेडिट पर पूर्ण 5/5 गुणवत्ता स्कोर और 4/5 गति स्कोर अर्जित करता है। प्लेटफ़ॉर्म उन परियोजनाओं के लिए डिज़ाइन किया गया है जिनमें वॉयस आउटपुट में सूक्ष्म भावनात्मक अभिव्यक्ति की आवश्यकता होती है, जैसे ऑडियोबुक कथन, चरित्र संवाद और भावनात्मक रूप से जागरूक आभासी सहायक। यह तीव्र जनरेशन को परिष्कृत भावनात्मक मॉडलिंग क्षमताओं के साथ संतुलित करता है जो कई तेज़ उपकरणों में कमी है। उन रचनाकारों के लिए जिन्हें गति और सूक्ष्म भावनात्मक बदलावों को व्यक्त करने की क्षमता दोनों की आवश्यकता है, Maya1 एक विशेष समाधान प्रदान करता है जो बाजार में एक विशिष्ट स्थान भरता है।
2026 में AI वॉयस जनरेशन का परिदृश्य कच्ची गति और आउटपुट गुणवत्ता के बीच एक स्पष्ट व्यापार-बंद द्वारा परिभाषित है, लेकिन अंतर तेजी से कम हो रहा है। MiniMax Speech 2.6 Turbo और Cartesia Sonic 3.5 Turbo जैसे मॉडल 50 मिलीसेकंड से कम की विलंबता पर जो संभव है उसकी सीमाओं को आगे बढ़ा रहे हैं, जबकि Index TTS 2.0 और Inworld Realtime TTS-2 जैसे प्लेटफ़ॉर्म साबित करते हैं कि उच्च निष्ठा और मजबूत गति सह-अस्तित्व में रह सकते हैं। हालांकि, सबसे महत्वपूर्ण प्रवृत्ति लागत में नाटकीय कमी है। Fish Audio का S2 मॉडल $15 प्रति मिलियन अक्षरों पर और Kokoro TTS $0.02 प्रति 1,000 अक्षरों पर उन टीमों के लिए तेज़, उच्च गुणवत्ता वाली वॉयस जनरेशन को सुलभ बना रहे हैं जो सिर्फ एक साल पहले कीमत से बाहर रहे होंगे। जैसे-जैसे ये प्रौद्योगिकियां परिपक्व होती रहेंगी, सिंथेटिक और मानव भाषण के बीच की रेखा को अलग करना तेजी से कठिन होता जाएगा, और गति रीयल-टाइम अनुप्रयोगों के लिए निर्णायक कारक बनी रहेगी।
Related Posts




1 Comment
Join the discussion and share your thoughts