Los 10 Generadores de Voz por IA Más Rápidos del Mundo en 2026


Table of Contents
La demanda de voz sintética instantánea y con sonido natural nunca ha sido tan alta. Desde transmisiones en vivo y agentes de IA conversacionales hasta servicio al cliente automatizado y producción rápida de contenido, la velocidad de generación de texto a voz (TTS) es ahora un factor competitivo crítico. Para elaborar esta clasificación, sopesamos criterios que incluyen la velocidad bruta de generación (medida en milisegundos de latencia), la calidad de salida (naturalidad, rango emocional y claridad), la eficiencia de costos (precio por carácter o por crédito) y la idoneidad para aplicaciones en tiempo real. Consultamos tablas de clasificación independientes como el Artificial Analysis Speech Arena y el HuggingFace TTS Arena, junto con guías de precios de API y análisis de expertos de 2026. El resultado es una lista de diez plataformas que representan el estado del arte en síntesis rápida de voz.
La Lista de los 10 Generadores de Voz por IA Más Rápidos de 2026:
1. MiniMax Speech 2.6 Turbo

MiniMax Speech 2.6 Turbo encabeza nuestra lista porque prioriza la velocidad por encima de todo sin sacrificar por completo la calidad de salida. Logra una latencia de extremo a extremo de menos de 250 milisegundos, lo que lo hace ideal para desarrolladores que necesitan salida de voz casi instantánea en aplicaciones en tiempo real. El modelo admite más de 40 idiomas y ofrece cientos de voces integradas. Con solo 6 créditos por uso, también ofrece un valor excepcional. La variante Turbo intercambia intencionalmente una pequeña cantidad de fidelidad de audio en comparación con su contraparte HD a cambio de una generación significativamente más rápida y un menor costo computacional. Esto lo convierte en la opción preferida para procesos de producción rápida de contenido y chatbots interactivos donde cada milisegundo cuenta.
2. ElevenLabs TTS Turbo v2.5

ElevenLabs ha sido durante mucho tiempo el punto de referencia en realismo de voz, y el modelo TTS Turbo v2.5 demuestra que la velocidad no tiene por qué ir en detrimento de la calidad. Esta versión ofrece tiempos de respuesta inferiores a 300 milisegundos, lo que permite una transmisión fluida para IA conversacional y contenido interactivo. Conserva los característicos patrones de respiración natural y la inflexión emocional de ElevenLabs, incluso a altas velocidades. Con un precio de $0.05 por cada 1,000 caracteres en la API de fal.ai, se sitúa en un nivel premium, pero está diseñado para equipos que requieren calidad de voz de grado humano en proyectos de respuesta rápida. Para aplicaciones donde tanto la velocidad como el realismo de la voz son innegociables, este modelo sigue siendo un fuerte contendiente.
3. VibeVoice 0.5B

VibeVoice 0.5B se gana su lugar como la mejor opción en relación calidad-precio entre los tres primeros. Ofrece una calidad excepcional en relación con su precio, con velocidades de generación rápidas y múltiples voces naturales disponibles por solo 6 créditos por uso. La arquitectura ligera del modelo permite una inferencia rápida sin necesidad de hardware costoso, lo que lo hace accesible para creadores independientes y pequeños estudios. Logra una conversión de texto a voz de alta velocidad mientras mantiene una salida de audio de sonido natural, logrando un equilibrio que muchos competidores no pueden igualar a este precio. Para los creadores que necesitan resultados fiables sin precios premium, VibeVoice es una opción destacada.
4. Index TTS 2.0

Index TTS 2.0 no es el generador más rápido de esta lista, pero tiene el honor de ser el generador de voz por IA mejor clasificado en general en 2026 según la evaluación exhaustiva de JAI Portal. Obtiene una puntuación perfecta de 5/5 en calidad, ofreciendo un habla realista y emocionalmente expresiva con capacidades avanzadas de clonación de voz y control de emociones. Con 15 créditos por uso y una puntuación de velocidad de 4/5, está diseñado para trabajos profesionales de locución y entornos de producción exigentes donde la fidelidad importa más que la velocidad bruta. La plataforma sobresale en equilibrar la velocidad de generación con la máxima fidelidad de salida posible, lo que la convierte en la herramienta preferida para estudios y agencias.
5. Maya Stream
Maya Stream está específicamente optimizado para aplicaciones de transmisión en tiempo real, y logra la rara hazaña de obtener una puntuación perfecta de 5/5 tanto en velocidad como en calidad simultáneamente. Está diseñado para creadores de contenido en vivo que necesitan generación de voz inmediata sin problemas de latencia durante transmisiones o sesiones interactivas. La plataforma mantiene una salida de audio de calidad de transmisión incluso en condiciones de streaming continuo, un desafío técnico que muchos competidores no han resuelto por completo. Con 15 créditos por uso, representa una opción premium para profesionales que no pueden tolerar ningún retraso en su proceso de generación de voz.
6. Fish Audio API (Modelo S2)
El modelo S2 de Fish Audio revoluciona el mercado con una combinación convincente de velocidad y eficiencia de costos. Ofrece tiempos de respuesta de streaming inferiores a 300 milisegundos, lo suficientemente rápido para IA conversacional en tiempo real y contenido interactivo. La estructura de precios de tarifa plana de aproximadamente $15 por millón de caracteres simplifica la elaboración de presupuestos en comparación con los sistemas basados en créditos, y representa una ventaja de costo dramática sobre competidores como ElevenLabs, que cobra aproximadamente $165 por millón de caracteres. El modelo S2 está construido sobre el motor de inferencia de código abierto SGLang, lo que permite a los desarrolladores autoalojarlo para tener control total sobre su infraestructura. La clonación de voz requiere solo 15 segundos de audio de muestra, y la plataforma cuenta con una biblioteca de más de 2 millones de voces. Para equipos que escalan funciones de voz a millones de usuarios, este precio por sí solo es transformador.
7. Cartesia Sonic 3.5 Turbo
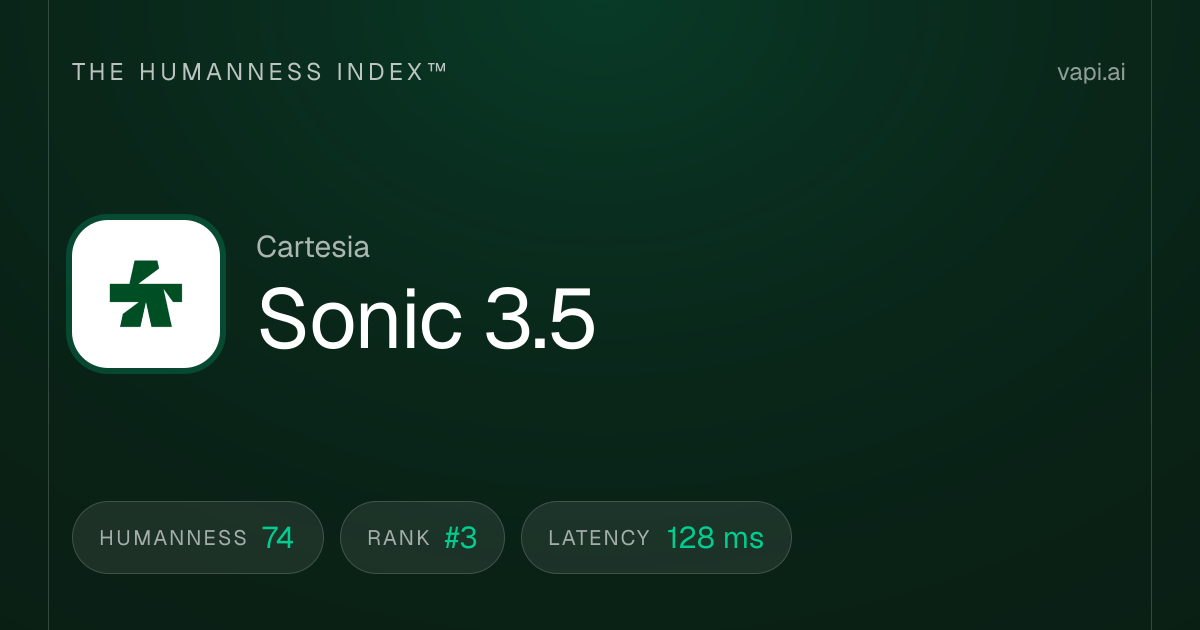
Cartesia Sonic 3.5 Turbo es el modelo más rápido de esta lista en una métrica crítica: el tiempo hasta el primer byte. Logra aproximadamente 40 milisegundos de latencia utilizando Modelos de Estado Espacial (SSM) en lugar de los transformadores utilizados por la mayoría de los competidores. Este tiempo de respuesta inferior a 50 milisegundos marca una diferencia perceptible en aplicaciones críticas de latencia, como sistemas de telefonía, agentes de servicio al cliente en vivo y experiencias interactivas donde incluso 200 milisegundos frente a 40 milisegundos se siente lento. La empresa recaudó $100 millones en financiamiento liderado por Kleiner Perkins, Index Ventures, Lightspeed y NVIDIA específicamente para optimizar estos casos de uso. En el Artificial Analysis Speech Arena, tiene una puntuación ELO de aproximadamente 1,204. Para desarrolladores que construyen interfaces de voz en tiempo real donde cada milisegundo importa, Cartesia es el líder indiscutible.
8. Inworld Realtime TTS-2

Inworld Realtime TTS-2 Research Preview es el modelo TTS en tiempo real mejor clasificado en tablas de clasificación independientes. Lidera tanto el Artificial Analysis Realtime TTS Arena con un ELO de aproximadamente 1,208 como el HuggingFace TTS Arena con un ELO de 1,578. Estas clasificaciones independientes tienen un peso significativo porque se basan en pruebas de escucha ciegas en lugar de afirmaciones de los proveedores. El modelo demostró una reducción de costos del 40% y un aumento del 4% en la retención de usuarios durante las pruebas A/B con Talkpal AI en más de 5 millones de usuarios. En un estudio de caso separado, Bible Chat escaló las funciones de voz por IA a millones de usuarios mientras reducía los costos en más del 90% en comparación con su proveedor de TTS anterior. Para organizaciones que priorizan el rendimiento verificado sobre las afirmaciones de marketing, el modelo de Inworld ofrece resultados probados a escala.
9. Kokoro TTS

Kokoro TTS ofrece la velocidad de generación más rápida entre las opciones económicas, con un precio de solo $0.02 por cada 1,000 caracteres en la plataforma fal.ai. Esto lo convierte en la opción ideal para equipos que necesitan generación rápida de voz al menor costo posible por carácter. A pesar de su bajo precio, ofrece una calidad de salida sólida adecuada para entornos de producción donde la eficiencia de costos es la principal preocupación. El modelo es particularmente adecuado para aplicaciones de alto volumen como narración automatizada, herramientas de accesibilidad y localización de contenido, donde la velocidad y la asequibilidad superan la necesidad de una calidad de voz absoluta. Para startups y equipos conscientes de los costos, Kokoro proporciona un punto de entrada notablemente rápido y funcional a la generación de voz por IA.
10. Maya1 TTS

Maya1 TTS completa nuestro top diez logrando fuertes velocidades de generación mientras se especializa en la entrega de voz emocional. Obtiene una puntuación perfecta de 5/5 en calidad y una puntuación de 4/5 en velocidad, con un precio de 15 créditos por uso. La plataforma está diseñada para proyectos que requieren una expresión emocional matizada en la salida de voz, como narración de audiolibros, diálogos de personajes y asistentes virtuales emocionalmente conscientes. Equilibra la generación rápida con capacidades sofisticadas de modelado emocional de las que carecen muchas herramientas más rápidas. Para los creadores que necesitan tanto velocidad como la capacidad de transmitir cambios emocionales sutiles, Maya1 ofrece una solución especializada que llena un nicho distintivo en el mercado.
El panorama de la generación de voz por IA en 2026 se define por un claro equilibrio entre la velocidad bruta y la calidad de salida, pero la brecha se está reduciendo rápidamente. Modelos como MiniMax Speech 2.6 Turbo y Cartesia Sonic 3.5 Turbo están empujando los límites de lo que es posible con una latencia inferior a 50 milisegundos, mientras que plataformas como Index TTS 2.0 e Inworld Realtime TTS-2 demuestran que la alta fidelidad y la gran velocidad pueden coexistir. Sin embargo, la tendencia más significativa es la reducción drástica de los costos. El modelo S2 de Fish Audio a $15 por millón de caracteres y Kokoro TTS a $0.02 por cada 1,000 caracteres están haciendo que la generación de voz rápida y de alta calidad sea accesible para equipos que habrían quedado excluidos por el precio hace solo un año. A medida que estas tecnologías continúan madurando, la línea entre el habla sintética y la humana será cada vez más difícil de distinguir, y la velocidad seguirá siendo el factor decisivo para las aplicaciones en tiempo real.
Related Posts




1 Comment
Join the discussion and share your thoughts