10 อันดับเครื่องสร้างเสียง AI ที่เร็วที่สุดในโลก ปี 2026


Table of Contents
ความต้องการเสียงสังเคราะห์ที่ฟังดูเป็นธรรมชาติและรวดเร็วทันใจนั้นไม่เคยสูงเท่านี้มาก่อน ตั้งแต่การสตรีมสด เอเจนต์ AI แบบสนทนา ไปจนถึงระบบบริการลูกค้าอัตโนมัติและการผลิตเนื้อหาที่รวดเร็ว ความเร็วในการสร้างข้อความเป็นเสียง (TTS) กลายเป็นปัจจัยการแข่งขันที่สำคัญยิ่ง ในการจัดอันดับนี้ เราได้ชั่งน้ำหนักเกณฑ์ต่างๆ รวมถึงความเร็วในการสร้างดิบ (วัดเป็นมิลลิวินาทีของเวลาแฝง) คุณภาพของผลลัพธ์ (ความเป็นธรรมชาติ ช่วงอารมณ์ และความชัดเจน) ความคุ้มค่าด้านต้นทุน (การกำหนดราคาต่อตัวอักษรหรือต่อเครดิต) และความเหมาะสมสำหรับแอปพลิเคชันแบบเรียลไทม์ เราได้ปรึกษากับกระดานผู้นำอิสระ เช่น Artificial Analysis Speech Arena และ HuggingFace TTS Arena พร้อมกับคู่มือราคา API และการวิเคราะห์จากผู้เชี่ยวชาญในปี 2026 ผลลัพธ์ที่ได้คือรายชื่อสิบแพลตฟอร์มที่เป็นตัวแทนของเทคโนโลยีล้ำสมัยในการสังเคราะห์เสียงที่รวดเร็ว
รายชื่อ 10 อันดับเครื่องสร้างเสียง AI ที่เร็วที่สุดในปี 2026:
1. MiniMax Speech 2.6 Turbo

MiniMax Speech 2.6 Turbo ครองตำแหน่งสูงสุดในรายการของเราเพราะให้ความสำคัญกับความเร็วเหนือสิ่งอื่นใด โดยไม่เสียสละคุณภาพของผลลัพธ์โดยสิ้นเชิง มันทำเวลาแฝงแบบ end-to-end ได้ต่ำกว่า 250 มิลลิวินาที ทำให้เหมาะอย่างยิ่งสำหรับนักพัฒนาที่ต้องการเอาต์พุตเสียงที่เกือบจะทันทีในแอปพลิเคชันแบบเรียลไทม์ โมเดลนี้รองรับมากกว่า 40 ภาษาและมีเสียงในตัวหลายร้อยเสียง ด้วยราคาเพียง 6 เครดิตต่อการใช้งานหนึ่งครั้ง มันยังให้ความคุ้มค่าที่ยอดเยี่ยมอีกด้วย รุ่น Turbo จงใจลดความเที่ยงตรงของเสียงลงเล็กน้อยเมื่อเทียบกับรุ่น HD เพื่อแลกกับความเร็วในการสร้างที่เร็วกว่าอย่างเห็นได้ชัดและต้นทุนการคำนวณที่ต่ำกว่า ทำให้เป็นตัวเลือกอันดับต้นๆ สำหรับสายการผลิตเนื้อหาที่รวดเร็วและแชทบอทแบบโต้ตอบที่ทุกมิลลิวินาทีมีความสำคัญ
2. ElevenLabs TTS Turbo v2.5

ElevenLabs เป็นเกณฑ์มาตรฐานด้านความสมจริงของเสียงมานานแล้ว และโมเดล TTS Turbo v2.5 พิสูจน์ให้เห็นว่าความเร็วไม่จำเป็นต้องแลกมาด้วยคุณภาพ เวอร์ชันนี้ให้เวลาตอบสนองต่ำกว่า 300 มิลลิวินาที ทำให้สามารถสตรีมได้อย่างราบรื่นสำหรับ AI แบบสนทนาและเนื้อหาแบบโต้ตอบ มันยังคงรักษารูปแบบการหายใจตามธรรมชาติอันเป็นเอกลักษณ์ของ ElevenLabs และการผันเสียงตามอารมณ์ แม้ในความเร็วสูง ด้วยราคา $0.05 ต่อ 1,000 ตัวอักษรบน API fal.ai มันอยู่ในระดับพรีเมียม แต่ถูกออกแบบมาสำหรับทีมที่ต้องการคุณภาพเสียงระดับมนุษย์ในโครงการที่ต้องดำเนินการอย่างรวดเร็ว สำหรับแอปพลิเคชันที่ทั้งความเร็วและความสมจริงของเสียงเป็นสิ่งที่ขาดไม่ได้ โมเดลนี้ยังคงเป็นคู่แข่งอันดับต้นๆ
3. VibeVoice 0.5B

VibeVoice 0.5B ได้รับตำแหน่งเป็นตัวเลือกที่คุ้มค่าที่สุดในสามอันดับแรก มันให้คุณภาพที่ยอดเยี่ยมเมื่อเทียบกับราคา ด้วยความเร็วในการสร้างที่รวดเร็วและเสียงที่เป็นธรรมชาติหลายแบบในราคาเพียง 6 เครดิตต่อการใช้งาน สถาปัตยกรรมที่มีน้ำหนักเบาของโมเดลช่วยให้การอนุมานรวดเร็วโดยไม่ต้องใช้ฮาร์ดแวร์ราคาแพง ทำให้ผู้สร้างอิสระและสตูดิโอขนาดเล็กสามารถเข้าถึงได้ มันทำการแปลงข้อความเป็นเสียงความเร็วสูงในขณะที่ยังคงรักษาเอาต์พุตเสียงที่ฟังดูเป็นธรรมชาติ สร้างสมดุลที่คู่แข่งหลายรายยากจะเทียบได้ในราคานี้ สำหรับผู้สร้างที่ต้องการผลลัพธ์ที่เชื่อถือได้โดยไม่ต้องจ่ายในราคาพรีเมียม VibeVoice เป็นตัวเลือกที่โดดเด่น
4. Index TTS 2.0

Index TTS 2.0 ไม่ใช่เครื่องสร้างเสียงที่เร็วที่สุดในรายการนี้ แต่มีความโดดเด่นในฐานะเครื่องสร้างเสียง AI ที่ได้รับการจัดอันดับสูงสุดโดยรวมในปี 2026 ตามการประเมินที่ครอบคลุมของ JAI Portal มันได้คะแนนเต็ม 5/5 ด้านคุณภาพ โดยให้เสียงที่สมจริงและแสดงอารมณ์ได้อย่างมีชีวิตชีวา พร้อมความสามารถในการโคลนเสียงขั้นสูงและการควบคุมอารมณ์ ด้วยราคา 15 เครดิตต่อการใช้งานและคะแนนความเร็ว 4/5 มันถูกออกแบบมาสำหรับงานพากย์เสียงมืออาชีพและสภาพแวดล้อมการผลิตที่มีความต้องการสูง ซึ่งความเที่ยงตรงมีความสำคัญมากกว่าความเร็วดิบ แพลตฟอร์มนี้มีความเป็นเลิศในการสร้างสมดุลระหว่างความเร็วในการสร้างกับความเที่ยงตรงของผลลัพธ์สูงสุด ทำให้เป็นเครื่องมือที่ต้องการสำหรับสตูดิโอและเอเจนซี่
5. Maya Stream
Maya Stream ได้รับการปรับให้เหมาะสมโดยเฉพาะสำหรับแอปพลิเคชันสตรีมมิ่งแบบเรียลไทม์ และประสบความสำเร็จที่หาได้ยากด้วยการได้คะแนนเต็ม 5/5 ทั้งในด้านความเร็วและคุณภาพพร้อมกัน มันถูกออกแบบมาสำหรับผู้สร้างเนื้อหาสดที่ต้องการสร้างเสียงทันทีโดยไม่มีปัญหาเวลาแฝงระหว่างการออกอากาศหรือเซสชันแบบโต้ตอบ แพลตฟอร์มรักษาคุณภาพเสียงระดับการออกอากาศได้แม้ภายใต้เงื่อนไขการสตรีมอย่างต่อเนื่อง ซึ่งเป็นความท้าทายทางเทคนิคที่คู่แข่งหลายรายยังแก้ไขได้ไม่สมบูรณ์ ด้วยราคา 15 เครดิตต่อการใช้งาน มันเป็นตัวเลือกระดับพรีเมียมสำหรับมืออาชีพที่ไม่สามารถทนต่อความล่าช้าใดๆ ในสายการผลิตเสียงของตนได้
6. Fish Audio API (S2 Model)
โมเดล S2 ของ Fish Audio สร้างความเปลี่ยนแปลงในตลาดด้วยการผสมผสานที่น่าสนใจระหว่างความเร็วและความคุ้มค่าด้านต้นทุน มันให้เวลาตอบสนองการสตรีมต่ำกว่า 300 มิลลิวินาที ซึ่งเร็วพอสำหรับ AI แบบสนทนาแบบเรียลไทม์และเนื้อหาแบบโต้ตอบ โครงสร้างราคาแบบอัตราคงที่ประมาณ $15 ต่อล้านตัวอักษรช่วยให้การจัดทำงบประมาณง่ายขึ้นเมื่อเทียบกับระบบที่ใช้เครดิต และแสดงถึงความได้เปรียบด้านต้นทุนอย่างมากเมื่อเทียบกับคู่แข่งอย่าง ElevenLabs ซึ่งคิดค่าบริการประมาณ $165 ต่อล้านตัวอักษร โมเดล S2 สร้างขึ้นบนเอ็นจิ้นการอนุมาน SGLang แบบโอเพนเวท ทำให้ผู้พัฒนาสามารถโฮสต์ด้วยตนเองเพื่อควบคุมโครงสร้างพื้นฐานได้อย่างเต็มที่ การโคลนเสียงต้องการตัวอย่างเสียงเพียง 15 วินาที และแพลตฟอร์มมีคลังเสียงมากกว่า 2 ล้านเสียง สำหรับทีมที่ขยายฟีเจอร์เสียงไปยังผู้ใช้หลายล้านคน การกำหนดราคานี้เพียงอย่างเดียวก็เป็นการเปลี่ยนแปลงครั้งใหญ่
7. Cartesia Sonic 3.5 Turbo
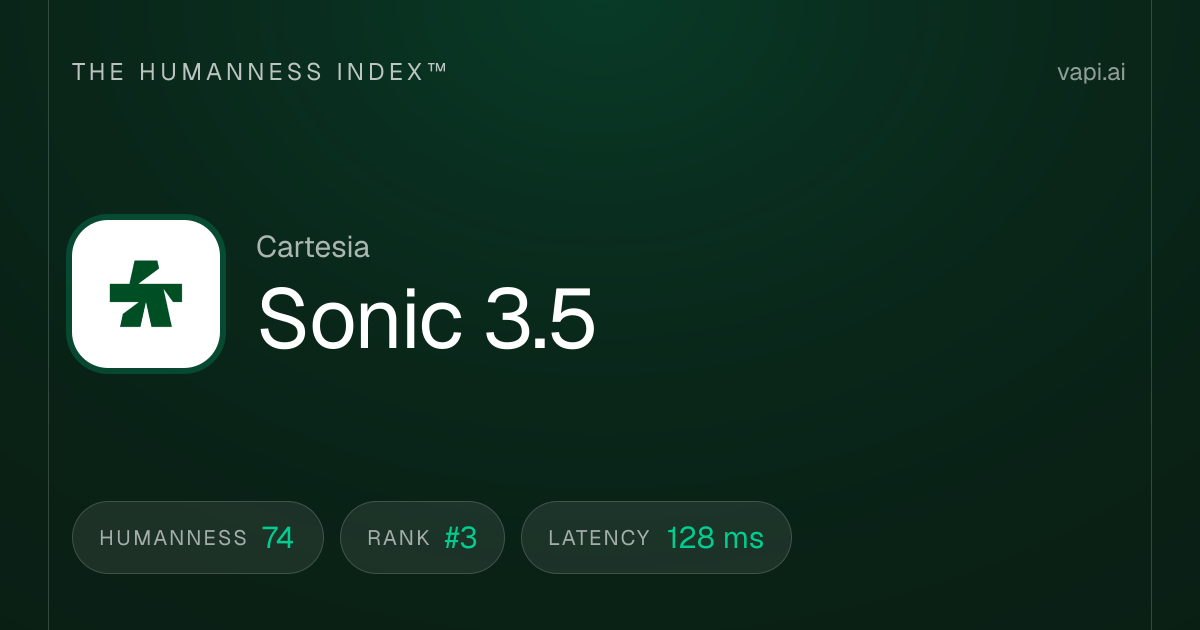
Cartesia Sonic 3.5 Turbo เป็นโมเดลที่เร็วที่สุดในรายการนี้โดยวัดจากเกณฑ์สำคัญหนึ่งข้อ นั่นคือ time-to-first-byte มันทำเวลาแฝงได้ประมาณ 40 มิลลิวินาที โดยใช้ State Space Models (SSMs) แทนทรานส์ฟอร์เมอร์ที่คู่แข่งส่วนใหญ่ใช้ เวลาตอบสนองที่ต่ำกว่า 50 มิลลิวินาทีนี้สร้างความแตกต่างที่รับรู้ได้ในแอปพลิเคชันที่ไวต่อเวลาแฝง เช่น ระบบโทรศัพท์ เอเจนต์บริการลูกค้าสด และประสบการณ์แบบโต้ตอบที่แม้แต่ 200 มิลลิวินาทีเทียบกับ 40 มิลลิวินาทีก็รู้สึกช้า บริษัทระดมทุนได้ 100 ล้านดอลลาร์ นำโดย Kleiner Perkins, Index Ventures, Lightspeed และ NVIDIA โดยเฉพาะเพื่อปรับให้เหมาะสมกับกรณีการใช้งานเหล่านี้ บน Artificial Analysis Speech Arena มันมีคะแนน ELO ประมาณ 1,204 สำหรับนักพัฒนาที่สร้างอินเทอร์เฟซเสียงแบบเรียลไทม์ที่ทุกมิลลิวินาทีมีความสำคัญ Cartesia คือผู้นำที่ชัดเจน
8. Inworld Realtime TTS-2

Inworld Realtime TTS-2 Research Preview เป็นโมเดล TTS แบบเรียลไทม์ที่ได้รับการจัดอันดับสูงสุดบนกระดานผู้นำอิสระ มันนำทั้ง Artificial Analysis Realtime TTS Arena ด้วยคะแนน ELO ประมาณ 1,208 และ HuggingFace TTS Arena ด้วยคะแนน ELO 1,578 การจัดอันดับอิสระเหล่านี้มีน้ำหนักมากเพราะอิงจากการทดสอบการฟังแบบปกปิด ไม่ใช่การอ้างสิทธิ์ของผู้ขาย โมเดลนี้แสดงให้เห็นถึงการลดต้นทุน 40% และการเพิ่มการรักษาผู้ใช้ 4% ระหว่างการทดสอบ A/B กับ Talkpal AI ในกลุ่มผู้ใช้มากกว่า 5 ล้านคน ในกรณีศึกษาแยกต่างหาก Bible Chat ขยายฟีเจอร์เสียง AI ไปยังผู้ใช้หลายล้านคนพร้อมลดต้นทุนลงกว่า 90% เมื่อเทียบกับผู้ให้บริการ TTS รายก่อนหน้า สำหรับองค์กรที่ให้ความสำคัญกับประสิทธิภาพที่ได้รับการตรวจสอบมากกว่าการกล่าวอ้างทางการตลาด โมเดลของ Inworld นำเสนอผลลัพธ์ที่พิสูจน์แล้วในระดับขนาดใหญ่
9. Kokoro TTS

Kokoro TTS นำเสนอความเร็วในการสร้างที่เร็วที่สุดในบรรดาตัวเลือกที่เป็นมิตรกับงบประมาณ โดยมีราคาเพียง $0.02 ต่อ 1,000 ตัวอักษรบนแพลตฟอร์ม fal.ai ทำให้เป็นตัวเลือกที่เหมาะสำหรับทีมที่ต้องการสร้างเสียงที่รวดเร็วด้วยต้นทุนต่อตัวอักษรที่ต่ำที่สุดเท่าที่จะเป็นไปได้ แม้จะมีราคาต่ำ แต่ก็ให้คุณภาพผลลัพธ์ที่มั่นคง เหมาะสำหรับสภาพแวดล้อมการผลิตที่ความคุ้มค่าด้านต้นทุนเป็นข้อกังวลหลัก โมเดลนี้เหมาะเป็นพิเศษสำหรับแอปพลิเคชันที่มีปริมาณมาก เช่น การบรรยายอัตโนมัติ เครื่องมือการเข้าถึง และการแปลเนื้อหาในท้องถิ่น ซึ่งความเร็วและราคาที่เอื้อมถึงมีความสำคัญมากกว่าความต้องการคุณภาพเสียงที่สมบูรณ์แบบ สำหรับสตาร์ทอัพและทีมที่คำนึงถึงต้นทุน Kokoro มอบจุดเริ่มต้นที่รวดเร็วและใช้งานได้จริงในการสร้างเสียง AI
10. Maya1 TTS

Maya1 TTS ปิดท้ายสิบอันดับแรกของเราด้วยการทำความเร็วในการสร้างที่แข็งแกร่งในขณะที่เชี่ยวชาญด้านการส่งเสียงที่สื่ออารมณ์ มันได้คะแนนคุณภาพเต็ม 5/5 และคะแนนความเร็ว 4/5 โดยมีราคา 15 เครดิตต่อการใช้งาน แพลตฟอร์มนี้ถูกออกแบบมาสำหรับโครงการที่ต้องการการแสดงออกทางอารมณ์ที่ละเอียดอ่อนในเอาต์พุตเสียง เช่น การบรรยายหนังสือเสียง บทสนทนาของตัวละคร และผู้ช่วยเสมือนที่ตระหนักถึงอารมณ์ มันสร้างสมดุลระหว่างการสร้างที่รวดเร็วกับความสามารถในการสร้างแบบจำลองอารมณ์ที่ซับซ้อน ซึ่งเครื่องมือที่เร็วกว่าหลายตัวขาด สำหรับผู้สร้างที่ต้องการทั้งความเร็วและความสามารถในการถ่ายทอดการเปลี่ยนแปลงทางอารมณ์ที่ละเอียดอ่อน Maya1 นำเสนอโซลูชันเฉพาะทางที่เติมเต็มช่องว่างที่ชัดเจนในตลาด
ภาพรวมของการสร้างเสียง AI ในปี 2026 ถูกกำหนดโดยการแลกเปลี่ยนที่ชัดเจนระหว่างความเร็วดิบและคุณภาพของผลลัพธ์ แต่ช่องว่างกำลังแคบลงอย่างรวดเร็ว โมเดลอย่าง MiniMax Speech 2.6 Turbo และ Cartesia Sonic 3.5 Turbo กำลังผลักดันขอบเขตของสิ่งที่เป็นไปได้ที่เวลาแฝงต่ำกว่า 50 มิลลิวินาที ในขณะที่แพลตฟอร์มอย่าง Index TTS 2.0 และ Inworld Realtime TTS-2 พิสูจน์ให้เห็นว่าความเที่ยงตรงสูงและความเร็วที่แข็งแกร่งสามารถอยู่ร่วมกันได้ อย่างไรก็ตาม แนวโน้มที่สำคัญที่สุดคือการลดต้นทุนอย่างมาก โมเดล S2 ของ Fish Audio ที่ราคา $15 ต่อล้านตัวอักษร และ Kokoro TTS ที่ราคา $0.02 ต่อ 1,000 ตัวอักษร กำลังทำให้การสร้างเสียงคุณภาพสูงและรวดเร็วเข้าถึงได้สำหรับทีมที่อาจถูกกีดกันด้วยราคาเมื่อปีที่แล้ว ในขณะที่เทคโนโลยีเหล่านี้ยังคงเติบโตเต็มที่ เส้นแบ่งระหว่างเสียงสังเคราะห์และเสียงมนุษย์จะแยกแยะได้ยากขึ้นเรื่อยๆ และความเร็วจะยังคงเป็นปัจจัยชี้ขาดสำหรับแอปพลิเคชันแบบเรียลไทม์
Related Posts




1 Comment
Join the discussion and share your thoughts