Топ-10 самых быстрых AI-генераторов голоса в мире 2026


Table of Contents
Спрос на мгновенную, естественно звучащую синтезированную речь никогда не был таким высоким. От прямых трансляций и диалоговых ИИ-агентов до автоматизированного обслуживания клиентов и быстрого создания контента — скорость генерации текста в речь (TTS) теперь является критическим конкурентным фактором. Для составления этого рейтинга мы оценили такие критерии, как скорость генерации (измеряемая в миллисекундах задержки), качество вывода (естественность, эмоциональный диапазон и четкость), экономическая эффективность (цена за символ или за кредит) и пригодность для приложений реального времени. Мы проконсультировались с независимыми рейтингами, такими как Artificial Analysis Speech Arena и HuggingFace TTS Arena, а также с руководствами по ценам на API и экспертными анализами за 2026 год. Результатом стал список из десяти платформ, представляющих передовые достижения в области быстрого синтеза голоса.
Список 10 самых быстрых AI-генераторов голоса 2026 года:
1. MiniMax Speech 2.6 Turbo

MiniMax Speech 2.6 Turbo занимает первое место в нашем списке, потому что ставит скорость превыше всего, не жертвуя при этом полностью качеством вывода. Он обеспечивает сквозную задержку менее 250 миллисекунд, что делает его идеальным для разработчиков, которым требуется почти мгновенный голосовой вывод в приложениях реального времени. Модель поддерживает более 40 языков и предлагает сотни встроенных голосов. При цене всего 6 кредитов за использование она также обеспечивает исключительную ценность. Вариант Turbo намеренно жертвует небольшим количеством аудиоточности по сравнению со своим HD-аналогом в обмен на значительно более быструю генерацию и меньшую вычислительную стоимость. Это делает его предпочтительным выбором для конвейеров быстрого создания контента и интерактивных чат-ботов, где важна каждая миллисекунда.
2. ElevenLabs TTS Turbo v2.5

ElevenLabs уже давно является эталоном реалистичности голоса, и модель TTS Turbo v2.5 доказывает, что скорость не обязательно должна идти в ущерб качеству. Эта версия обеспечивает время отклика менее 300 миллисекунд, обеспечивая плавную потоковую передачу для диалогового ИИ и интерактивного контента. Она сохраняет фирменные для ElevenLabs естественные паттерны дыхания и эмоциональную интонацию даже на высоких скоростях. При цене $0,05 за 1000 символов через API fal.ai, она находится на премиальном уровне, но предназначена для команд, которым требуется качество голоса на уровне человеческого в проектах с быстрым оборотом. Для приложений, где скорость и реалистичность голоса являются обязательными условиями, эта модель остается одним из главных претендентов.
3. VibeVoice 0.5B

VibeVoice 0.5B заслуживает свое место как лучший вариант по соотношению цены и качества в первой тройке. Он обеспечивает исключительное качество относительно своей цены, с высокой скоростью генерации и несколькими естественными голосами, доступными всего за 6 кредитов за использование. Легкая архитектура модели обеспечивает быстрый вывод без необходимости в дорогом оборудовании, что делает ее доступной для независимых создателей и небольших студий. Она обеспечивает высокоскоростное преобразование текста в речь, сохраняя при этом естественно звучащий аудиовыход, достигая баланса, который многие конкуренты с трудом могут повторить в этом ценовом диапазоне. Для создателей, которым нужны надежные результаты без премиального ценообразования, VibeVoice является выдающимся выбором.
4. Index TTS 2.0

Index TTS 2.0 не является самым быстрым генератором в этом списке, но он имеет отличие как лучший AI-генератор голоса в 2026 году по версии всесторонней оценки JAI Portal. Он получает идеальную оценку 5/5 за качество, предлагая реалистичную, эмоционально выразительную речь с расширенными возможностями клонирования голоса и управления эмоциями. При цене 15 кредитов за использование и оценке скорости 4/5, он предназначен для профессиональной озвучки и требовательных производственных сред, где точность важнее сырой скорости. Платформа превосходно балансирует скорость генерации с максимально возможной точностью вывода, что делает ее предпочтительным инструментом для студий и агентств.
5. Maya Stream
Maya Stream специально оптимизирована для потоковых приложений реального времени и достигает редкого результата, получая идеальные оценки 5/5 как по скорости, так и по качеству одновременно. Она разработана для создателей живого контента, которым требуется мгновенная генерация голоса без проблем с задержкой во время трансляций или интерактивных сессий. Платформа поддерживает аудиовыход вещательного качества даже в условиях непрерывной потоковой передачи — техническая задача, которую многие конкуренты еще не полностью решили. При цене 15 кредитов за использование, это премиальный вариант для профессионалов, которые не могут допустить никакой задержки в своем конвейере генерации голоса.
6. Fish Audio API (S2 Model)
Модель S2 от Fish Audio разрушает рынок убедительным сочетанием скорости и экономической эффективности. Она обеспечивает время отклика в потоковом режиме менее 300 миллисекунд, что достаточно быстро для диалогового ИИ реального времени и интерактивного контента. Структура ценообразования с фиксированной ставкой примерно $15 за миллион символов упрощает бюджетирование по сравнению с системами на основе кредитов и представляет собой значительное ценовое преимущество перед конкурентами, такими как ElevenLabs, которые взимают примерно $165 за миллион символов. Модель S2 построена на движке вывода SGLang с открытыми весами, что позволяет разработчикам самостоятельно размещать ее для полного контроля над своей инфраструктурой. Для клонирования голоса требуется всего 15 секунд аудиосэмпла, а платформа может похвастаться библиотекой из более чем 2 миллионов голосов. Для команд, масштабирующих голосовые функции для миллионов пользователей, только это ценообразование является преобразующим.
7. Cartesia Sonic 3.5 Turbo
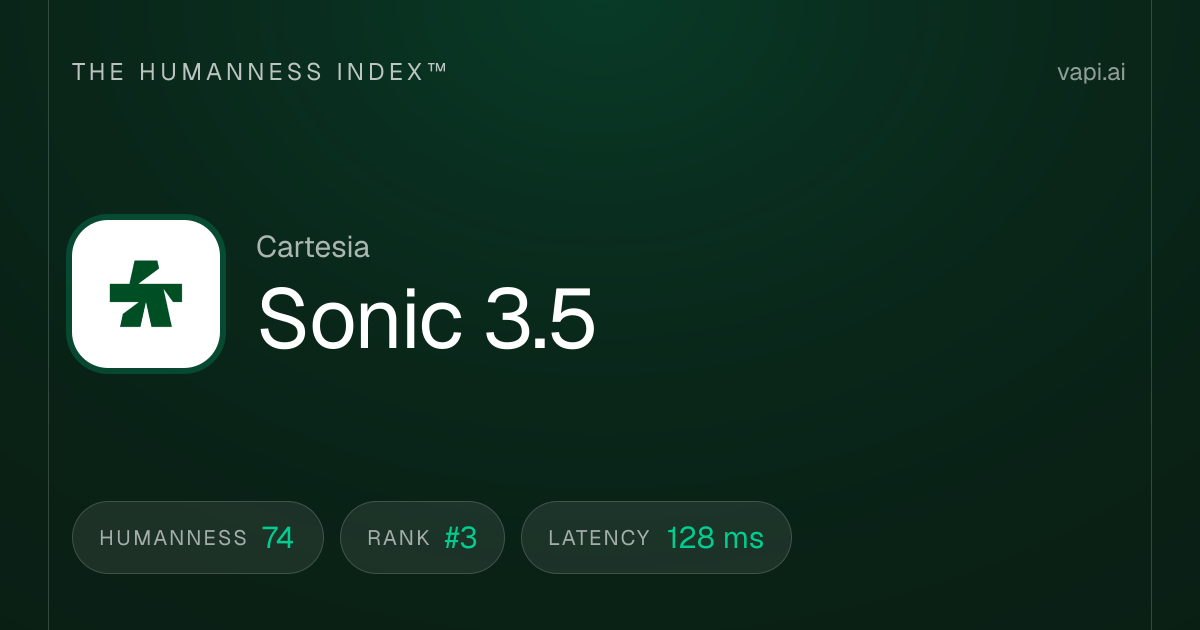
Cartesia Sonic 3.5 Turbo является самой быстрой моделью в этом списке по одному критическому показателю: времени до первого байта. Она достигает задержки примерно 40 миллисекунд, используя модели пространства состояний (SSM) вместо трансформеров, используемых большинством конкурентов. Это время отклика менее 50 миллисекунд делает ощутимую разницу в приложениях, критичных к задержке, таких как телефонные системы, живые агенты обслуживания клиентов и интерактивные впечатления, где даже 200 миллисекунд по сравнению с 40 миллисекундами кажутся медленными. Компания привлекла $100 миллионов финансирования под руководством Kleiner Perkins, Index Ventures, Lightspeed и NVIDIA специально для оптимизации этих случаев использования. На Artificial Analysis Speech Arena она имеет рейтинг ELO примерно 1,204. Для разработчиков, создающих голосовые интерфейсы реального времени, где важна каждая миллисекунда, Cartesia является явным лидером.
8. Inworld Realtime TTS-2

Inworld Realtime TTS-2 Research Preview является лучшей моделью TTS реального времени по версии независимых рейтингов. Она лидирует как в Artificial Analysis Realtime TTS Arena с ELO примерно 1,208, так и в HuggingFace TTS Arena с ELO 1,578. Эти независимые рейтинги имеют значительный вес, поскольку основаны на слепых прослушиваниях, а не на заявлениях вендоров. Модель продемонстрировала снижение затрат на 40% и повышение удержания пользователей на 4% во время A/B-тестирования с Talkpal AI среди более чем 5 миллионов пользователей. В отдельном тематическом исследовании Bible Chat масштабировал голосовые функции ИИ для миллионов пользователей, одновременно снизив затраты более чем на 90% по сравнению с предыдущим поставщиком TTS. Для организаций, которые ставят проверенную производительность выше маркетинговых заявлений, модель Inworld предлагает доказанные результаты в масштабе.
9. Kokoro TTS

Kokoro TTS предлагает самую высокую скорость генерации среди бюджетных вариантов, цена составляет всего $0,02 за 1000 символов на платформе fal.ai. Это делает его идеальным выбором для команд, которым нужна быстрая генерация голоса с наименьшей возможной стоимостью за символ. Несмотря на низкую цену, он обеспечивает качественный вывод, подходящий для производственных сред, где экономическая эффективность является главным приоритетом. Модель особенно хорошо подходит для высокообъемных приложений, таких как автоматизированное озвучивание, инструменты доступности и локализация контента, где скорость и доступность перевешивают необходимость в абсолютном качестве голоса. Для стартапов и команд, заботящихся о бюджете, Kokoro предоставляет замечательно быструю и функциональную точку входа в мир генерации голоса с помощью ИИ.
10. Maya1 TTS

Maya1 TTS замыкает нашу десятку лучших, достигая высокой скорости генерации, специализируясь при этом на эмоциональной голосовой передаче. Она получает идеальную оценку качества 5/5 и оценку скорости 4/5, цена составляет 15 кредитов за использование. Платформа предназначена для проектов, требующих нюансированного эмоционального выражения в голосовом выводе, таких как озвучивание аудиокниг, диалоги персонажей и эмоционально осведомленные виртуальные ассистенты. Она балансирует быструю генерацию с изощренными возможностями эмоционального моделирования, которых не хватает многим более быстрым инструментам. Для создателей, которым нужны как скорость, так и способность передавать тонкие эмоциональные сдвиги, Maya1 предлагает специализированное решение, заполняющее определенную нишу на рынке.
Ландшафт генерации голоса с помощью ИИ в 2026 году определяется четким компромиссом между сырой скоростью и качеством вывода, но этот разрыв быстро сокращается. Такие модели, как MiniMax Speech 2.6 Turbo и Cartesia Sonic 3.5 Turbo, раздвигают границы возможного при задержке менее 50 миллисекунд, в то время как такие платформы, как Index TTS 2.0 и Inworld Realtime TTS-2, доказывают, что высокая точность и высокая скорость могут сосуществовать. Однако наиболее значимой тенденцией является резкое снижение стоимости. Модель S2 от Fish Audio по цене $15 за миллион символов и Kokoro TTS по цене $0,02 за 1000 символов делают быструю и качественную генерацию голоса доступной для команд, которые еще год назад были бы исключены из-за цены. По мере того как эти технологии продолжают развиваться, грань между синтезированной и человеческой речью будет становиться все более трудноразличимой, а скорость останется решающим фактором для приложений реального времени.
Related Posts




1 Comment
Join the discussion and share your thoughts