Top 10 Geradores de Voz por IA Mais Rápidos do Mundo em 2026


Table of Contents
A demanda por fala sintética instantânea e com som natural nunca foi tão alta. Desde transmissões ao vivo e agentes de IA conversacionais até atendimento ao cliente automatizado e produção rápida de conteúdo, a velocidade da geração de texto para fala (TTS) é agora um fator competitivo crítico. Para construir este ranking, ponderamos critérios incluindo velocidade bruta de geração (medida em milissegundos de latência), qualidade da saída (naturalidade, alcance emocional e clareza), eficiência de custo (preço por caractere ou por crédito) e adequação para aplicações em tempo real. Consultamos rankings independentes como o Artificial Analysis Speech Arena e o HuggingFace TTS Arena, juntamente com guias de preços de API e análises de especialistas de 2026. O resultado é uma lista de dez plataformas que representam o estado da arte em síntese rápida de voz.
A Lista dos 10 Geradores de Voz por IA Mais Rápidos de 2026:
1. MiniMax Speech 2.6 Turbo

O MiniMax Speech 2.6 Turbo está no topo da nossa lista porque prioriza a velocidade acima de tudo, sem sacrificar completamente a qualidade da saída. Ele atinge uma latência de ponta a ponta inferior a 250 milissegundos, tornando-o ideal para desenvolvedores que precisam de saída de voz quase instantânea em aplicações em tempo real. O modelo suporta mais de 40 idiomas e oferece centenas de vozes integradas. Com apenas 6 créditos por uso, também oferece um valor excepcional. A variante Turbo intencionalmente troca uma pequena quantidade de fidelidade de áudio em comparação com sua contraparte HD em troca de uma geração significativamente mais rápida e menor custo computacional. Isso o torna a escolha ideal para pipelines de produção rápida de conteúdo e chatbots interativos onde cada milissegundo conta.
2. ElevenLabs TTS Turbo v2.5

A ElevenLabs tem sido há muito tempo a referência em realismo de voz, e o modelo TTS Turbo v2.5 prova que a velocidade não precisa vir às custas da qualidade. Esta versão oferece tempos de resposta abaixo de 300 milissegundos, permitindo streaming contínuo para IA conversacional e conteúdo interativo. Ela mantém os padrões naturais de respiração e inflexão emocional característicos da ElevenLabs, mesmo em altas velocidades. Com preço de $0,05 por 1.000 caracteres na API fal.ai, está em um nível premium, mas é projetado para equipes que exigem qualidade de voz com nível humano em projetos de rápida execução. Para aplicações onde tanto a velocidade quanto o realismo da voz são inegociáveis, este modelo continua sendo um dos principais concorrentes.
3. VibeVoice 0.5B

O VibeVoice 0.5B conquista seu lugar como a melhor opção de custo-benefício entre os três primeiros. Ele oferece qualidade excepcional em relação ao seu preço, com velocidades de geração rápidas e múltiplas vozes naturais disponíveis por apenas 6 créditos por uso. A arquitetura leve do modelo permite inferência rápida sem exigir hardware caro, tornando-o acessível para criadores independentes e pequenos estúdios. Ele alcança conversão de texto em fala em alta velocidade, mantendo uma saída de áudio com som natural, equilibrando algo que muitos concorrentes têm dificuldade em igualar neste preço. Para criadores que precisam de resultados confiáveis sem preços premium, o VibeVoice é uma escolha de destaque.
4. Index TTS 2.0

O Index TTS 2.0 não é o gerador mais rápido desta lista, mas tem a distinção de ser o gerador de voz por IA mais bem classificado em 2026, de acordo com a avaliação abrangente do JAI Portal. Ele obtém uma pontuação perfeita de 5/5 em qualidade, oferecendo fala realista e emocionalmente expressiva com recursos avançados de clonagem de voz e controle de emoção. Com 15 créditos por uso e uma pontuação de velocidade de 4/5, é projetado para trabalhos profissionais de narração e ambientes de produção exigentes onde a fidelidade importa mais do que a velocidade bruta. A plataforma se destaca em equilibrar a velocidade de geração com a mais alta fidelidade de saída possível, tornando-a a ferramenta preferida para estúdios e agências.
5. Maya Stream
O Maya Stream é especificamente otimizado para aplicações de streaming em tempo real e alcança o feito raro de obter uma pontuação perfeita de 5/5 tanto em velocidade quanto em qualidade simultaneamente. Ele é projetado para criadores de conteúdo ao vivo que precisam de geração de voz imediata sem problemas de latência durante transmissões ou sessões interativas. A plataforma mantém a qualidade de áudio de transmissão mesmo sob condições contínuas de streaming, um desafio técnico que muitos concorrentes não resolveram completamente. Com 15 créditos por uso, representa uma opção premium para profissionais que não podem tolerar qualquer atraso em seu pipeline de geração de voz.
6. Fish Audio API (Modelo S2)
O modelo S2 da Fish Audio revoluciona o mercado com uma combinação convincente de velocidade e eficiência de custo. Ele oferece tempos de resposta em streaming abaixo de 300 milissegundos, rápido o suficiente para IA conversacional em tempo real e conteúdo interativo. A estrutura de preços de taxa fixa de aproximadamente $15 por milhão de caracteres simplifica o orçamento em comparação com sistemas baseados em crédito e representa uma vantagem de custo dramática sobre concorrentes como a ElevenLabs, que cobra cerca de $165 por milhão de caracteres. O modelo S2 é construído no mecanismo de inferência SGLang de pesos abertos, permitindo que desenvolvedores auto-hospedem para controle total sobre sua infraestrutura. A clonagem de voz requer apenas 15 segundos de áudio de amostra, e a plataforma possui uma biblioteca de mais de 2 milhões de vozes. Para equipes que escalam recursos de voz para milhões de usuários, este preço por si só é transformador.
7. Cartesia Sonic 3.5 Turbo
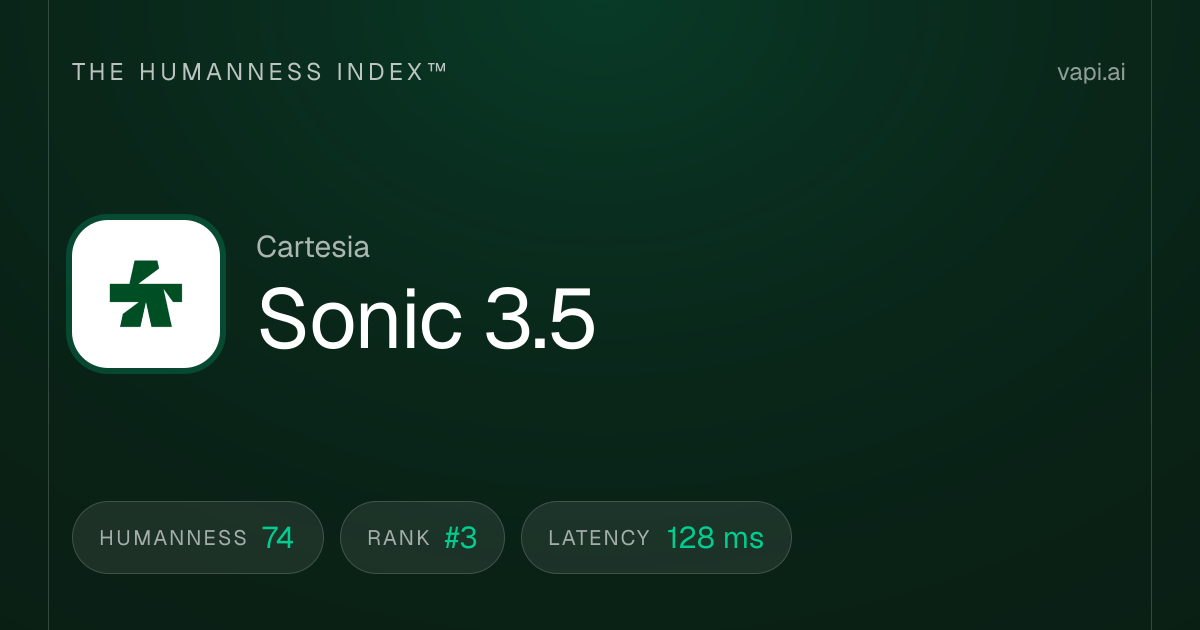
O Cartesia Sonic 3.5 Turbo é o modelo mais rápido desta lista em uma métrica crítica: tempo até o primeiro byte. Ele atinge aproximadamente 40 milissegundos de latência usando Modelos de Espaço de Estados (SSMs) em vez dos transformadores usados pela maioria dos concorrentes. Este tempo de resposta abaixo de 50 milissegundos faz uma diferença perceptível em aplicações críticas de latência, como sistemas de telefonia, agentes de atendimento ao cliente ao vivo e experiências interativas onde mesmo 200 milissegundos versus 40 milissegundos parecem lentos. A empresa arrecadou $100 milhões em financiamento liderado por Kleiner Perkins, Index Ventures, Lightspeed e NVIDIA especificamente para otimizar esses casos de uso. No Artificial Analysis Speech Arena, ele possui uma pontuação ELO de aproximadamente 1.204. Para desenvolvedores que constroem interfaces de voz em tempo real onde cada milissegundo importa, a Cartesia é a líder clara.
8. Inworld Realtime TTS-2

O Inworld Realtime TTS-2 Research Preview é o modelo TTS em tempo real mais bem classificado em rankings independentes. Ele lidera tanto o Artificial Analysis Realtime TTS Arena com um ELO de aproximadamente 1.208 quanto o HuggingFace TTS Arena com um ELO de 1.578. Esses rankings independentes têm peso significativo porque são baseados em testes de audição cega, e não em alegações de fornecedores. O modelo demonstrou uma redução de 40% nos custos e um aumento de 4% na retenção de usuários durante testes A/B com a Talkpal AI em mais de 5 milhões de usuários. Em um estudo de caso separado, o Bible Chat escalou recursos de voz por IA para milhões de usuários enquanto reduzia os custos em mais de 90% em comparação com seu provedor de TTS anterior. Para organizações que priorizam desempenho verificado em vez de alegações de marketing, o modelo da Inworld oferece resultados comprovados em escala.
9. Kokoro TTS

O Kokoro TTS oferece a velocidade de geração mais rápida entre as opções de baixo custo, com preço de apenas $0,02 por 1.000 caracteres na plataforma fal.ai. Isso o torna a escolha ideal para equipes que precisam de geração rápida de voz ao menor custo por caractere possível. Apesar do baixo preço, ele oferece qualidade de saída sólida, adequada para ambientes de produção onde a eficiência de custo é a principal preocupação. O modelo é particularmente adequado para aplicações de alto volume, como narração automatizada, ferramentas de acessibilidade e localização de conteúdo, onde velocidade e acessibilidade superam a necessidade de qualidade de voz absoluta. Para startups e equipes preocupadas com custos, o Kokoro fornece um ponto de entrada notavelmente rápido e funcional na geração de voz por IA.
10. Maya1 TTS

O Maya1 TTS completa nosso top dez alcançando fortes velocidades de geração enquanto se especializa na entrega de voz emocional. Ele obtém uma pontuação perfeita de 5/5 em qualidade e uma pontuação de 4/5 em velocidade, com preço de 15 créditos por uso. A plataforma é projetada para projetos que exigem expressão emocional matizada na saída de voz, como narração de audiolivros, diálogo de personagens e assistentes virtuais emocionalmente conscientes. Ele equilibra a geração rápida com capacidades sofisticadas de modelagem emocional que muitas ferramentas mais rápidas não possuem. Para criadores que precisam tanto de velocidade quanto da capacidade de transmitir mudanças emocionais sutis, o Maya1 oferece uma solução especializada que preenche um nicho distinto no mercado.
O cenário da geração de voz por IA em 2026 é definido por uma troca clara entre velocidade bruta e qualidade de saída, mas a diferença está diminuindo rapidamente. Modelos como MiniMax Speech 2.6 Turbo e Cartesia Sonic 3.5 Turbo estão ultrapassando os limites do que é possível com latência abaixo de 50 milissegundos, enquanto plataformas como Index TTS 2.0 e Inworld Realtime TTS-2 provam que alta fidelidade e boa velocidade podem coexistir. A tendência mais significativa, no entanto, é a redução dramática nos custos. O modelo S2 da Fish Audio a $15 por milhão de caracteres e o Kokoro TTS a $0,02 por 1.000 caracteres estão tornando a geração de voz rápida e de alta qualidade acessível para equipes que teriam sido excluídas por preço há apenas um ano. À medida que essas tecnologias continuam a amadurecer, a linha entre a fala sintética e humana se tornará cada vez mais difícil de distinguir, e a velocidade continuará sendo o fator decisivo para aplicações em tempo real.
Related Posts




1 Comment
Join the discussion and share your thoughts