10 Generator Suara AI Tercepat di Dunia Tahun 2026


Table of Contents
Permintaan akan ucapan sintetis yang instan dan terdengar alami belum pernah setinggi ini. Mulai dari siaran langsung dan agen AI percakapan hingga layanan pelanggan otomatis dan produksi konten cepat, kecepatan pembuatan teks-ke-ucapan (TTS) kini menjadi faktor persaingan yang krusial. Untuk menyusun peringkat ini, kami mempertimbangkan kriteria termasuk kecepatan pembuatan mentah (diukur dalam milidetik latensi), kualitas keluaran (kewajaran, rentang emosi, dan kejelasan), efisiensi biaya (harga per karakter atau per kredit), serta kesesuaian untuk aplikasi waktu nyata. Kami berkonsultasi dengan papan peringkat independen seperti Artificial Analysis Speech Arena dan HuggingFace TTS Arena, bersama dengan panduan harga API dan analisis ahli dari tahun 2026. Hasilnya adalah daftar sepuluh platform yang mewakili teknologi terdepan dalam sintesis suara cepat.
Daftar 10 Generator Suara AI Tercepat Tahun 2026:
1. MiniMax Speech 2.6 Turbo

MiniMax Speech 2.6 Turbo berada di puncak daftar kami karena mengutamakan kecepatan di atas segalanya tanpa sepenuhnya mengorbankan kualitas keluaran. Model ini mencapai latensi ujung-ke-ujung di bawah 250 milidetik, menjadikannya ideal bagi pengembang yang membutuhkan keluaran suara hampir instan dalam aplikasi waktu nyata. Model ini mendukung lebih dari 40 bahasa dan menawarkan ratusan suara bawaan. Dengan hanya 6 kredit per penggunaan, model ini juga memberikan nilai yang luar biasa. Varian Turbo sengaja mengorbankan sedikit fidelitas audio dibandingkan dengan versi HD-nya dengan imbalan pembuatan yang jauh lebih cepat dan biaya komputasi yang lebih rendah. Ini menjadikannya pilihan utama untuk jalur produksi konten cepat dan chatbot interaktif di mana setiap milidetik sangat berarti.
2. ElevenLabs TTS Turbo v2.5

ElevenLabs telah lama menjadi tolok ukur untuk realisme suara, dan model TTS Turbo v2.5 membuktikan bahwa kecepatan tidak harus mengorbankan kualitas. Versi ini memberikan waktu respons di bawah 300 milidetik, memungkinkan streaming yang mulus untuk AI percakapan dan konten interaktif. Model ini mempertahankan pola pernapasan alami dan infleksi emosional khas ElevenLabs, bahkan pada kecepatan tinggi. Dengan harga $0,05 per 1.000 karakter di API fal.ai, model ini berada di tingkat premium tetapi dirancang untuk tim yang membutuhkan kualitas suara setara manusia dalam proyek dengan waktu penyelesaian cepat. Untuk aplikasi di mana kecepatan dan realisme suara tidak dapat ditawar, model ini tetap menjadi pesaing utama.
3. VibeVoice 0.5B

VibeVoice 0.5B mendapatkan tempatnya sebagai opsi nilai terbaik di tiga besar. Model ini memberikan kualitas luar biasa relatif terhadap harganya, dengan kecepatan pembuatan yang cepat dan beberapa suara alami yang tersedia hanya dengan 6 kredit per penggunaan. Arsitektur ringan model ini memungkinkan inferensi cepat tanpa memerlukan perangkat keras yang mahal, membuatnya dapat diakses oleh kreator independen dan studio kecil. Model ini mencapai konversi teks-ke-ucapan berkecepatan tinggi sambil mempertahankan keluaran audio yang terdengar alami, menciptakan keseimbangan yang sulit ditandingi banyak pesaing pada titik harga ini. Bagi kreator yang membutuhkan hasil andal tanpa harga premium, VibeVoice adalah pilihan yang menonjol.
4. Index TTS 2.0

Index TTS 2.0 bukanlah generator tercepat mutlak dalam daftar ini, tetapi memiliki keistimewaan sebagai generator suara AI peringkat teratas secara keseluruhan pada tahun 2026 menurut evaluasi komprehensif JAI Portal. Model ini mendapatkan skor sempurna 5/5 untuk kualitas, menawarkan ucapan yang hidup dan ekspresif secara emosional dengan kemampuan kloning suara dan kontrol emosi yang canggih. Dengan 15 kredit per penggunaan dan skor kecepatan 4/5, model ini dirancang untuk pekerjaan sulih suara profesional dan lingkungan produksi yang menuntut di mana fidelitas lebih penting daripada kecepatan mentah. Platform ini unggul dalam menyeimbangkan kecepatan pembuatan dengan fidelitas keluaran setinggi mungkin, menjadikannya alat pilihan untuk studio dan agensi.
5. Maya Stream
Maya Stream dioptimalkan secara khusus untuk aplikasi streaming waktu nyata, dan mencapai prestasi langka dengan mendapatkan skor sempurna 5/5 dalam kecepatan dan kualitas secara bersamaan. Platform ini dirancang untuk kreator konten langsung yang membutuhkan pembuatan suara instan tanpa masalah latensi selama siaran atau sesi interaktif. Platform ini mempertahankan kualitas audio setara siaran bahkan dalam kondisi streaming berkelanjutan, sebuah tantangan teknis yang belum sepenuhnya dipecahkan oleh banyak pesaing. Dengan 15 kredit per penggunaan, ini mewakili opsi premium bagi profesional yang tidak dapat mentolerir penundaan apa pun dalam jalur pembuatan suara mereka.
6. Fish Audio API (Model S2)
Model S2 dari Fish Audio mengganggu pasar dengan kombinasi kecepatan dan efisiensi biaya yang menarik. Model ini memberikan waktu respons streaming di bawah 300 milidetik, cukup cepat untuk AI percakapan waktu nyata dan konten interaktif. Struktur harga tarif tetap sekitar $15 per juta karakter menyederhanakan penganggaran dibandingkan dengan sistem berbasis kredit, dan mewakili keunggulan biaya yang dramatis dibandingkan pesaing seperti ElevenLabs, yang mengenakan biaya sekitar $165 per juta karakter. Model S2 dibangun di atas mesin inferensi SGLang dengan bobot terbuka, memungkinkan pengembang untuk menghosting sendiri untuk kontrol penuh atas infrastruktur mereka. Kloning suara hanya membutuhkan 15 detik sampel audio, dan platform ini memiliki pustaka lebih dari 2 juta suara. Bagi tim yang meningkatkan fitur suara hingga jutaan pengguna, harga ini sendiri bersifat transformatif.
7. Cartesia Sonic 3.5 Turbo
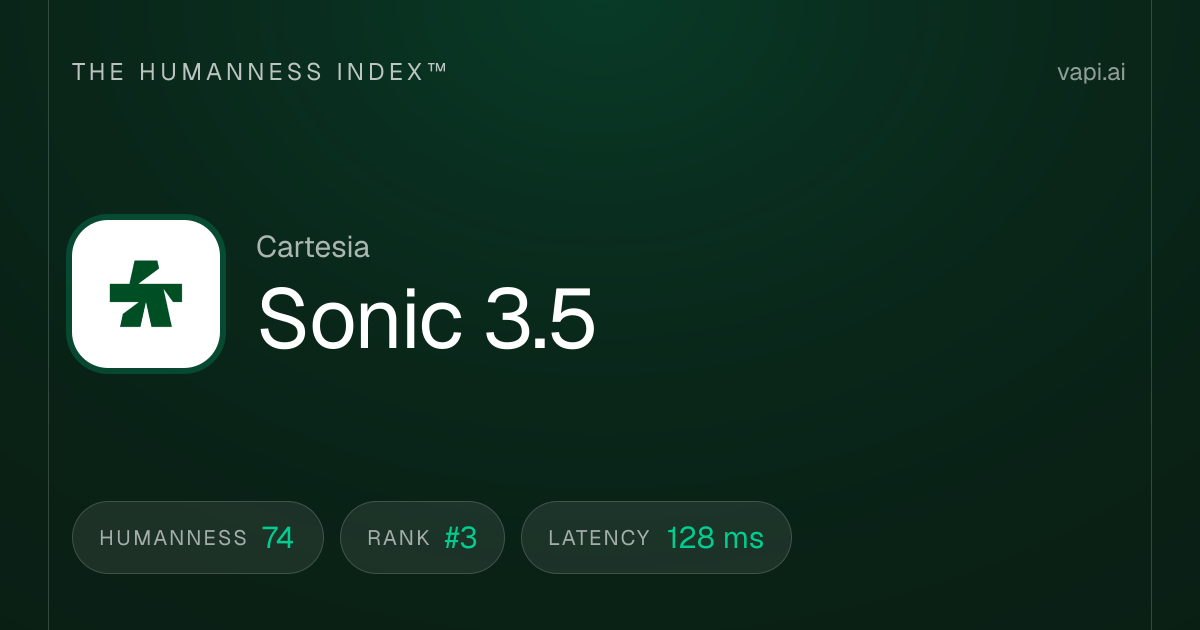
Cartesia Sonic 3.5 Turbo adalah model tercepat mutlak dalam daftar ini berdasarkan satu metrik kritis: waktu hingga byte pertama. Model ini mencapai latensi sekitar 40 milidetik menggunakan Model Ruang Keadaan (SSM) sebagai pengganti transformer yang digunakan oleh sebagian besar pesaing. Waktu respons di bawah 50 milidetik ini membuat perbedaan yang terasa dalam aplikasi yang kritis terhadap latensi seperti sistem telepon, agen layanan pelanggan langsung, dan pengalaman interaktif di mana bahkan 200 milidetik versus 40 milidetik terasa lamban. Perusahaan ini mengumpulkan dana $100 juta yang dipimpin oleh Kleiner Perkins, Index Ventures, Lightspeed, dan NVIDIA khusus untuk mengoptimalkan kasus penggunaan ini. Di Artificial Analysis Speech Arena, model ini memegang skor ELO sekitar 1.204. Bagi pengembang yang membangun antarmuka suara waktu nyata di mana setiap milidetik berarti, Cartesia adalah pemimpin yang jelas.
8. Inworld Realtime TTS-2

Pratinjau Riset Inworld Realtime TTS-2 adalah model TTS waktu nyata peringkat teratas di papan peringkat independen. Model ini memimpin Artificial Analysis Realtime TTS Arena dengan ELO sekitar 1.208 dan HuggingFace TTS Arena dengan ELO 1.578. Peringkat independen ini memiliki bobot yang signifikan karena didasarkan pada tes pendengaran buta, bukan klaim vendor. Model ini menunjukkan pengurangan biaya sebesar 40% dan peningkatan retensi pengguna sebesar 4% selama pengujian A/B dengan Talkpal AI di lebih dari 5 juta pengguna. Dalam studi kasus terpisah, Bible Chat meningkatkan fitur suara AI hingga jutaan pengguna sambil mengurangi biaya lebih dari 90% dibandingkan dengan penyedia TTS sebelumnya. Bagi organisasi yang memprioritaskan kinerja terverifikasi di atas klaim pemasaran, model Inworld menawarkan hasil yang terbukti dalam skala besar.
9. Kokoro TTS

Kokoro TTS menawarkan kecepatan pembuatan tercepat di antara opsi ramah anggaran, dengan harga hanya $0,02 per 1.000 karakter di platform fal.ai. Ini menjadikannya pilihan ideal bagi tim yang membutuhkan pembuatan suara cepat dengan biaya per karakter serendah mungkin. Meskipun harganya murah, model ini memberikan kualitas keluaran yang solid yang cocok untuk lingkungan produksi di mana efisiensi biaya menjadi perhatian utama. Model ini sangat cocok untuk aplikasi volume tinggi seperti narasi otomatis, alat aksesibilitas, dan lokalisasi konten, di mana kecepatan dan keterjangkauan lebih diutamakan daripada kualitas suara mutlak. Bagi perusahaan rintisan dan tim yang sadar biaya, Kokoro menyediakan titik masuk yang sangat cepat dan fungsional ke dalam pembuatan suara AI.
10. Maya1 TTS

Maya1 TTS melengkapi sepuluh besar kami dengan mencapai kecepatan pembuatan yang kuat sambil mengkhususkan diri dalam penyampaian suara emosional. Platform ini mendapatkan skor kualitas sempurna 5/5 dan skor kecepatan 4/5, dengan harga 15 kredit per penggunaan. Platform ini dirancang untuk proyek yang membutuhkan ekspresi emosional yang bernuansa dalam keluaran suara, seperti narasi buku audio, dialog karakter, dan asisten virtual yang sadar emosi. Platform ini menyeimbangkan pembuatan cepat dengan kemampuan pemodelan emosional canggih yang tidak dimiliki banyak alat yang lebih cepat. Bagi kreator yang membutuhkan kecepatan dan kemampuan untuk menyampaikan perubahan emosional yang halus, Maya1 menawarkan solusi khusus yang mengisi ceruk pasar yang berbeda.
Lanskap pembuatan suara AI pada tahun 2026 ditentukan oleh pertukaran yang jelas antara kecepatan mentah dan kualitas keluaran, tetapi kesenjangan ini menyempit dengan cepat. Model seperti MiniMax Speech 2.6 Turbo dan Cartesia Sonic 3.5 Turbo mendorong batas-batas dari apa yang mungkin dilakukan pada latensi di bawah 50 milidetik, sementara platform seperti Index TTS 2.0 dan Inworld Realtime TTS-2 membuktikan bahwa fidelitas tinggi dan kecepatan kuat dapat hidup berdampingan. Namun, tren yang paling signifikan adalah pengurangan biaya yang dramatis. Model S2 Fish Audio seharga $15 per juta karakter dan Kokoro TTS seharga $0,02 per 1.000 karakter membuat pembuatan suara berkualitas tinggi dan cepat dapat diakses oleh tim yang setahun lalu mungkin tidak mampu membelinya. Seiring teknologi ini terus matang, batas antara ucapan sintetis dan manusia akan menjadi semakin sulit dibedakan, dan kecepatan akan tetap menjadi faktor penentu untuk aplikasi waktu nyata.
Related Posts




1 Comment
Join the discussion and share your thoughts