Top 10 des générateurs de voix IA les plus rapides au monde en 2026


Table of Contents
La demande de parole synthétique instantanée et naturelle n'a jamais été aussi élevée. Du streaming en direct et des agents conversationnels d'IA au service client automatisé et à la production rapide de contenu, la vitesse de génération de la synthèse vocale (TTS) est désormais un facteur concurrentiel critique. Pour établir ce classement, nous avons pondéré des critères incluant la vitesse de génération brute (mesurée en millisecondes de latence), la qualité de sortie (naturel, gamme émotionnelle et clarté), l'efficacité des coûts (tarification par caractère ou par crédit), et l'adéquation aux applications en temps réel. Nous avons consulté des classements indépendants tels que l'Artificial Analysis Speech Arena et le HuggingFace TTS Arena, ainsi que des guides de tarification d'API et des analyses d'experts de 2026. Le résultat est une liste de dix plateformes qui représentent l'état de l'art en matière de synthèse vocale rapide.
La liste des 10 générateurs de voix IA les plus rapides en 2026 :
1. MiniMax Speech 2.6 Turbo

MiniMax Speech 2.6 Turbo trône en tête de notre liste car il privilégie la vitesse avant tout sans sacrifier complètement la qualité de sortie. Il atteint une latence de bout en bout inférieure à 250 millisecondes, ce qui le rend idéal pour les développeurs ayant besoin d'une sortie vocale quasi instantanée dans des applications en temps réel. Le modèle prend en charge plus de 40 langues et propose des centaines de voix intégrées. À seulement 6 crédits par utilisation, il offre également un rapport qualité-prix exceptionnel. La variante Turbo échange intentionnellement une petite partie de la fidélité audio par rapport à son homologue HD en échange d'une génération nettement plus rapide et d'un coût de calcul réduit. Cela en fait le choix privilégié pour les pipelines de production de contenu rapide et les chatbots interactifs où chaque milliseconde compte.
2. ElevenLabs TTS Turbo v2.5

ElevenLabs est depuis longtemps la référence en matière de réalisme vocal, et le modèle TTS Turbo v2.5 prouve que la vitesse ne doit pas se faire au détriment de la qualité. Cette version offre des temps de réponse inférieurs à 300 millisecondes, permettant un streaming fluide pour l'IA conversationnelle et le contenu interactif. Elle conserve les schémas respiratoires naturels et l'inflexion émotionnelle caractéristiques d'ElevenLabs, même à grande vitesse. Tarifé à 0,05 $ pour 1 000 caractères sur l'API fal.ai, il se situe à un niveau premium mais est conçu pour les équipes qui nécessitent une qualité vocale de niveau humain dans des projets à délais serrés. Pour les applications où la vitesse et le réalisme vocal sont non négociables, ce modèle reste un concurrent de premier plan.
3. VibeVoice 0.5B

VibeVoice 0.5B mérite sa place comme la meilleure option rapport qualité-prix dans le top trois. Il offre une qualité exceptionnelle par rapport à son prix, avec des vitesses de génération rapides et plusieurs voix naturelles disponibles pour seulement 6 crédits par utilisation. L'architecture légère du modèle permet une inférence rapide sans nécessiter de matériel coûteux, le rendant accessible aux créateurs indépendants et aux petits studios. Il réalise une conversion texte-parole à grande vitesse tout en maintenant une sortie audio au son naturel, trouvant un équilibre que de nombreux concurrents peinent à atteindre à ce prix. Pour les créateurs qui ont besoin de résultats fiables sans tarification premium, VibeVoice est un choix remarquable.
4. Index TTS 2.0

Index TTS 2.0 n'est pas le générateur le plus rapide de cette liste, mais il détient la distinction d'être le générateur de voix IA le mieux classé en 2026 selon l'évaluation complète de JAI Portal. Il obtient un score parfait de 5/5 pour la qualité, offrant une parole réaliste et émotionnellement expressive avec des capacités avancées de clonage vocal et de contrôle des émotions. À 15 crédits par utilisation et avec un score de vitesse de 4/5, il est conçu pour le travail de voix off professionnel et les environnements de production exigeants où la fidélité prime sur la vitesse brute. La plateforme excelle à équilibrer la vitesse de génération avec la plus haute fidélité de sortie possible, ce qui en fait l'outil préféré des studios et des agences.
5. Maya Stream
Maya Stream est spécifiquement optimisé pour les applications de streaming en temps réel, et il réalise l'exploit rare d'obtenir un score parfait de 5/5 à la fois en vitesse et en qualité. Il est conçu pour les créateurs de contenu en direct qui ont besoin d'une génération vocale immédiate sans problèmes de latence lors des diffusions ou des sessions interactives. La plateforme maintient une qualité audio de diffusion même dans des conditions de streaming continu, un défi technique que de nombreux concurrents n'ont pas entièrement résolu. À 15 crédits par utilisation, il représente une option premium pour les professionnels qui ne peuvent tolérer aucun délai dans leur pipeline de génération vocale.
6. Fish Audio API (Modèle S2)
Le modèle S2 de Fish Audio bouleverse le marché avec une combinaison convaincante de vitesse et d'efficacité des coûts. Il offre des temps de réponse en streaming inférieurs à 300 millisecondes, assez rapides pour l'IA conversationnelle en temps réel et le contenu interactif. La structure tarifaire à taux fixe d'environ 15 $ par million de caractères simplifie la budgétisation par rapport aux systèmes basés sur les crédits, et représente un avantage de coût considérable par rapport à des concurrents comme ElevenLabs, qui facture environ 165 $ par million de caractères. Le modèle S2 est construit sur le moteur d'inférence open-weights SGLang, permettant aux développeurs de l'héberger eux-mêmes pour un contrôle total de leur infrastructure. Le clonage vocal ne nécessite que 15 secondes d'échantillon audio, et la plateforme dispose d'une bibliothèque de plus de 2 millions de voix. Pour les équipes qui déploient des fonctionnalités vocales à des millions d'utilisateurs, cette tarification à elle seule est transformatrice.
7. Cartesia Sonic 3.5 Turbo
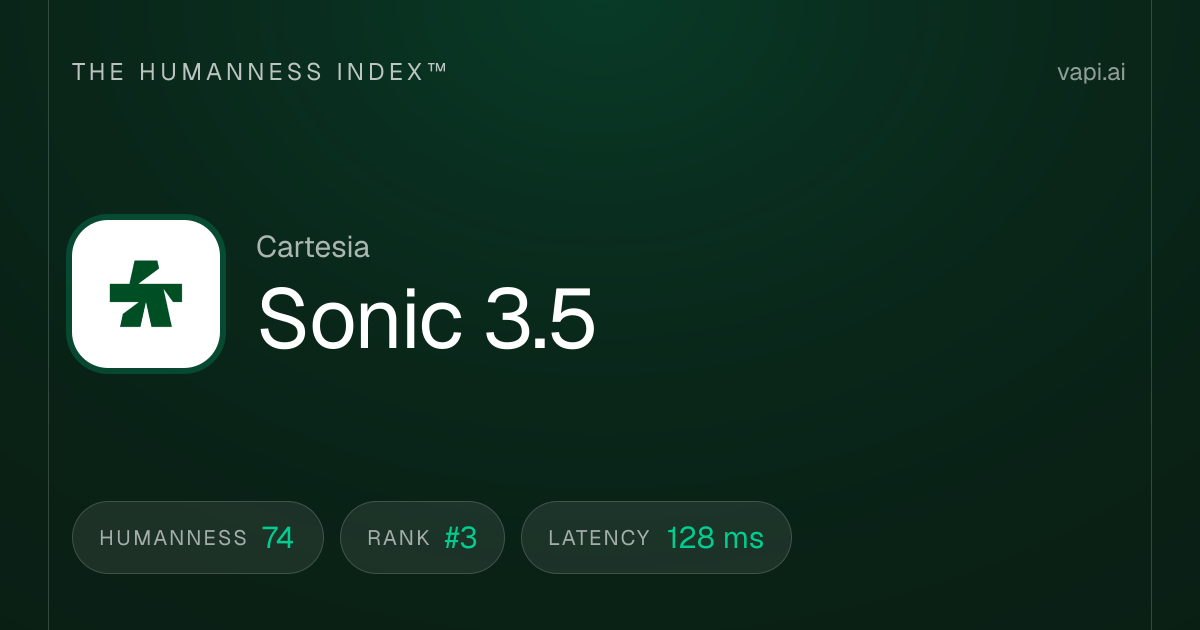
Cartesia Sonic 3.5 Turbo est le modèle le plus rapide de cette liste selon une métrique critique : le temps jusqu'au premier octet. Il atteint environ 40 millisecondes de latence en utilisant des modèles d'espace d'état (SSM) au lieu des transformeurs utilisés par la plupart des concurrents. Ce temps de réponse inférieur à 50 millisecondes fait une différence perceptible dans les applications critiques en termes de latence telles que les systèmes téléphoniques, les agents de service client en direct et les expériences interactives où même 200 millisecondes contre 40 millisecondes semble lent. L'entreprise a levé 100 millions de dollars de financement mené par Kleiner Perkins, Index Ventures, Lightspeed et NVIDIA spécifiquement pour optimiser ces cas d'utilisation. Sur l'Artificial Analysis Speech Arena, il détient un score ELO d'environ 1 204. Pour les développeurs construisant des interfaces vocales en temps réel où chaque milliseconde compte, Cartesia est le leader incontesté.
8. Inworld Realtime TTS-2

Inworld Realtime TTS-2 Research Preview est le modèle TTS en temps réel le mieux classé sur les classements indépendants. Il mène à la fois l'Artificial Analysis Realtime TTS Arena avec un ELO d'environ 1 208 et le HuggingFace TTS Arena avec un ELO de 1 578. Ces classements indépendants ont un poids considérable car ils sont basés sur des tests d'écoute à l'aveugle plutôt que sur des affirmations des fournisseurs. Le modèle a démontré une réduction des coûts de 40 % et une augmentation de 4 % de la rétention des utilisateurs lors de tests A/B avec Talkpal AI auprès de plus de 5 millions d'utilisateurs. Dans une étude de cas distincte, Bible Chat a étendu les fonctionnalités vocales IA à des millions d'utilisateurs tout en réduisant les coûts de plus de 90 % par rapport à leur précédent fournisseur TTS. Pour les organisations qui privilégient les performances vérifiées aux affirmations marketing, le modèle d'Inworld offre des résultats éprouvés à grande échelle.
9. Kokoro TTS

Kokoro TTS offre la vitesse de génération la plus rapide parmi les options économiques, tarifé à seulement 0,02 $ pour 1 000 caractères sur la plateforme fal.ai. Cela en fait le choix idéal pour les équipes qui ont besoin d'une génération vocale rapide au coût par caractère le plus bas possible. Malgré son prix bas, il offre une qualité de sortie solide adaptée aux environnements de production où l'efficacité des coûts est la préoccupation principale. Le modèle est particulièrement adapté aux applications à volume élevé telles que la narration automatisée, les outils d'accessibilité et la localisation de contenu, où la vitesse et l'abordabilité l'emportent sur le besoin de qualité vocale absolue. Pour les startups et les équipes soucieuses des coûts, Kokoro offre un point d'entrée remarquablement rapide et fonctionnel dans la génération de voix IA.
10. Maya1 TTS

Maya1 TTS complète notre top dix en atteignant de fortes vitesses de génération tout en se spécialisant dans la diffusion vocale émotionnelle. Il obtient un score parfait de 5/5 pour la qualité et un score de 4/5 pour la vitesse, tarifé à 15 crédits par utilisation. La plateforme est conçue pour les projets qui nécessitent une expression émotionnelle nuancée dans la sortie vocale, tels que la narration de livres audio, le dialogue de personnages et les assistants virtuels conscients des émotions. Il équilibre la génération rapide avec des capacités de modélisation émotionnelle sophistiquées que de nombreux outils plus rapides ne possèdent pas. Pour les créateurs qui ont besoin à la fois de vitesse et de la capacité à transmettre des changements émotionnels subtils, Maya1 offre une solution spécialisée qui occupe une niche distincte sur le marché.
Le paysage de la génération vocale IA en 2026 est défini par un compromis clair entre vitesse brute et qualité de sortie, mais l'écart se réduit rapidement. Des modèles comme MiniMax Speech 2.6 Turbo et Cartesia Sonic 3.5 Turbo repoussent les limites du possible avec une latence inférieure à 50 millisecondes, tandis que des plateformes comme Index TTS 2.0 et Inworld Realtime TTS-2 prouvent qu'une haute fidélité et une bonne vitesse peuvent coexister. La tendance la plus significative, cependant, est la réduction spectaculaire des coûts. Le modèle S2 de Fish Audio à 15 $ par million de caractères et Kokoro TTS à 0,02 $ pour 1 000 caractères rendent la génération vocale rapide et de haute qualité accessible aux équipes qui auraient été exclues il y a seulement un an. Alors que ces technologies continuent de mûrir, la frontière entre la parole synthétique et humaine deviendra de plus en plus difficile à distinguer, et la vitesse restera le facteur décisif pour les applications en temps réel.
Related Posts




1 Comment
Join the discussion and share your thoughts