أسرع 10 مولدات صوت بالذكاء الاصطناعي في العالم لعام 2026


Table of Contents
لم يكن الطلب على الكلام الاصطناعي الفوري والطبيعي أعلى من أي وقت مضى. من البث المباشر وعوامل الذكاء الاصطناعي التحادثية إلى خدمة العملاء الآلية والإنتاج السريع للمحتوى، أصبحت سرعة توليد النص إلى كلام (TTS) عاملاً تنافسياً حاسماً الآن. لبناء هذا التصنيف، قمنا بوزن المعايير بما في ذلك سرعة التوليد الخام (مقاسة بالمللي ثانية من زمن الاستجابة)، وجودة المخرجات (الطبيعية، والنطاق العاطفي، والوضوح)، وكفاءة التكلفة (التسعير لكل حرف أو لكل رصيد)، والملاءمة للتطبيقات في الوقت الفعلي. استشرنا لوحات المتصدرين المستقلة مثل Artificial Analysis Speech Arena و HuggingFace TTS Arena، إلى جانب أدلة تسعير واجهات برمجة التطبيقات (API) وتحليلات الخبراء من عام 2026. والنتيجة هي قائمة تضم عشر منصات تمثل أحدث ما توصلت إليه التكنولوجيا في التوليف الصوتي السريع.
قائمة أفضل 10 مولدات صوت بالذكاء الاصطناعي الأسرع في عام 2026:
1. MiniMax Speech 2.6 Turbo

يأتي MiniMax Speech 2.6 Turbo على رأس قائمتنا لأنه يعطي الأولوية للسرعة قبل كل شيء دون التضحية تماماً بجودة المخرجات. يحقق زمن استجابة شامل يقل عن 250 مللي ثانية، مما يجعله مثالياً للمطورين الذين يحتاجون إلى مخرجات صوتية فورية تقريباً في التطبيقات في الوقت الفعلي. يدعم النموذج أكثر من 40 لغة ويقدم مئات الأصوات المدمجة. بسعر 6 أرصدة فقط لكل استخدام، فإنه يوفر أيضاً قيمة استثنائية. يتنازل متغير Turbo عمداً عن قدر ضئيل من دقة الصوت مقارنة بنظيره HD مقابل توليد أسرع بكثير وتكلفة حسابية أقل. وهذا يجعله الخيار الأمثل لخطوط إنتاج المحتوى السريع وروبوتات الدردشة التفاعلية حيث كل ملي ثانية مهمة.
2. ElevenLabs TTS Turbo v2.5

لطالما كانت ElevenLabs هي المعيار لواقعية الصوت، ويثبت نموذج TTS Turbo v2.5 أن السرعة لا يجب أن تأتي على حساب الجودة. يوفر هذا الإصدار أوقات استجابة أقل من 300 مللي ثانية، مما يتيح البث السلس للذكاء الاصطناعي التحادثي والمحتوى التفاعلي. يحتفظ بأنماط التنفس الطبيعية المميزة لـ ElevenLabs والنبرة العاطفية، حتى عند السرعات العالية. بسعر 0.05 دولار لكل 1000 حرف على واجهة برمجة التطبيقات fal.ai، فهو يقع في مستوى متميز ولكنه مصمم للفرق التي تتطلب جودة صوت بشرية في مشاريع سريعة الإنجاز. بالنسبة للتطبيقات حيث تكون كل من السرعة وواقعية الصوت أمراً لا يقبل المساومة، يظل هذا النموذج منافساً قوياً.
3. VibeVoice 0.5B

يكسب VibeVoice 0.5B مكانه كأفضل خيار من حيث القيمة بين الثلاثة الأوائل. إنه يقدم جودة استثنائية مقارنة بسعره، مع سرعات توليد سريعة وأصوات طبيعية متعددة متاحة بسعر 6 أرصدة فقط لكل استخدام. تتيح البنية خفيفة الوزن للنموذج استدلالاً سريعاً دون الحاجة إلى أجهزة باهظة الثمن، مما يجعله في متناول المبدعين المستقلين والاستوديوهات الصغيرة. يحقق تحويلاً عالي السرعة من النص إلى كلام مع الحفاظ على مخرجات صوتية طبيعية، محققاً توازناً يكافح العديد من المنافسين لمطابقته عند هذه النقطة السعرية. بالنسبة للمبدعين الذين يحتاجون إلى نتائج موثوقة بدون أسعار متميزة، يعتبر VibeVoice خياراً بارزاً.
4. Index TTS 2.0

Index TTS 2.0 ليس أسرع مولد على الإطلاق في هذه القائمة، لكنه يحمل تمييز كونه أفضل مولد صوت بالذكاء الاصطناعي تصنيفاً بشكل عام في عام 2026 وفقاً للتقييم الشامل لبوابة JAI. يحصل على درجة كاملة 5/5 للجودة، حيث يقدم كلاماً نابضاً بالحياة ومعبراً عاطفياً مع إمكانيات متقدمة لاستنساخ الصوت والتحكم في المشاعر. بسعر 15 رصيداً لكل استخدام ودرجة سرعة 4/5، فهو مصمم لأعمال التعليق الصوتي الاحترافية وبيئات الإنتاج المتطلبة حيث تكون الدقة أهم من السرعة الخام. تتفوق المنصة في الموازنة بين سرعة التوليد وأعلى دقة ممكنة للمخرجات، مما يجعلها الأداة المفضلة للاستوديوهات والوكالات.
5. Maya Stream
Maya Stream محسّن خصيصاً لتطبيقات البث في الوقت الفعلي، ويحقق الإنجاز النادر بحصوله على درجة كاملة 5/5 في كل من السرعة والجودة في وقت واحد. إنه مصمم لمنشئي المحتوى المباشر الذين يحتاجون إلى توليد صوت فوري دون مشاكل زمن الوصول أثناء البث أو الجلسات التفاعلية. تحافظ المنصة على جودة صوت على مستوى البث حتى في ظل ظروف البث المستمر، وهو تحدٍ تقني لم تحله العديد من المنافسين بشكل كامل. بسعر 15 رصيداً لكل استخدام، فهو يمثل خياراً متميزاً للمحترفين الذين لا يمكنهم تحمل أي تأخير في خط توليد الصوت لديهم.
6. Fish Audio API (S2 Model)
يعطل نموذج S2 من Fish Audio السوق بمزيج مقنع من السرعة وكفاءة التكلفة. إنه يوفر أوقات استجابة للبث أقل من 300 مللي ثانية، وهي سريعة بما يكفي للذكاء الاصطناعي التحادثي في الوقت الفعلي والمحتوى التفاعلي. هيكل التسعير بمعدل ثابت يبلغ حوالي 15 دولاراً لكل مليون حرف يبسط إعداد الميزانية مقارنة بالأنظمة القائمة على الأرصدة، ويمثل ميزة تكلفة هائلة مقارنة بالمنافسين مثل ElevenLabs التي تتقاضى حوالي 165 دولاراً لكل مليون حرف. تم بناء نموذج S2 على محرك الاستدلال مفتوح الأوزان SGLang، مما يسمح للمطورين بالاستضافة الذاتية للتحكم الكامل في البنية التحتية الخاصة بهم. يتطلب استنساخ الصوت 15 ثانية فقط من عينة الصوت، وتفتخر المنصة بمكتبة تضم أكثر من 2 مليون صوت. بالنسبة للفرق التي تقوم بتوسيع نطاق ميزات الصوت لملايين المستخدمين، فإن هذا التسعير وحده يعتبر تحويلياً.
7. Cartesia Sonic 3.5 Turbo
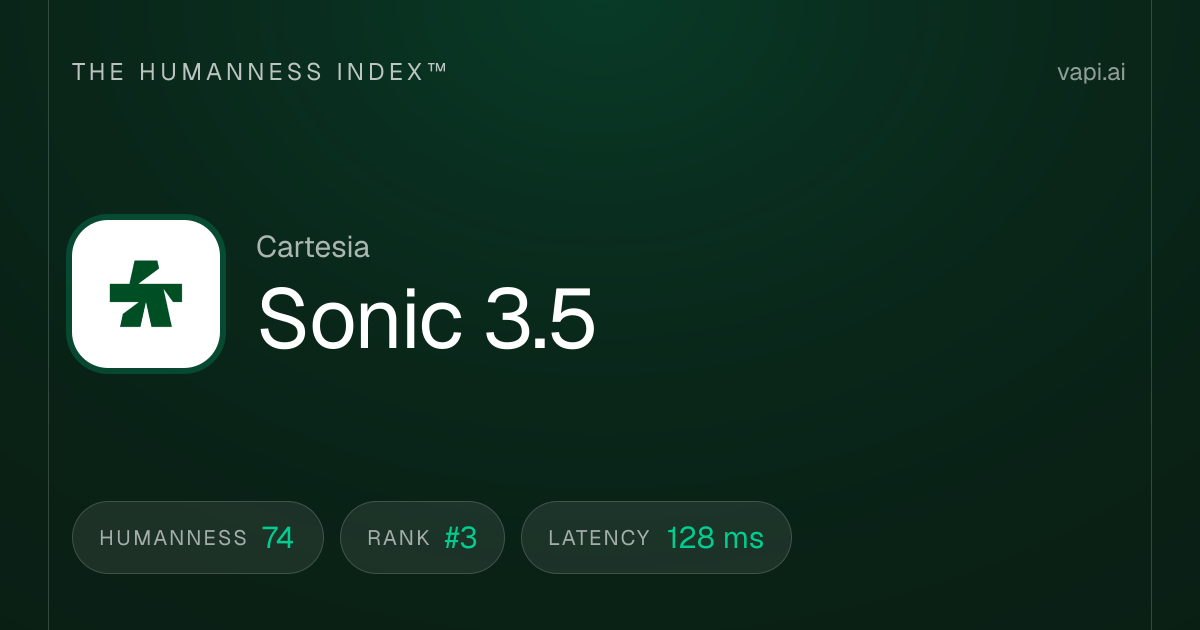
Cartesia Sonic 3.5 Turbo هو أسرع نموذج على الإطلاق في هذه القائمة بمقياس حاسم واحد: الوقت حتى أول بايت. إنه يحقق زمن استجابة يبلغ حوالي 40 مللي ثانية باستخدام نماذج فضاء الحالة (SSMs) بدلاً من المحولات التي يستخدمها معظم المنافسين. وقت الاستجابة الذي يقل عن 50 مللي ثانية هذا يحدث فرقاً ملحوظاً في التطبيقات الحساسة لزمن الوصول مثل أنظمة الهاتف، وعملاء خدمة العملاء المباشرين، والتجارب التفاعلية حيث حتى 200 مللي ثانية مقابل 40 مللي ثانية تبدو بطيئة. جمعت الشركة 100 مليون دولار من التمويل بقيادة Kleiner Perkins و Index Ventures و Lightspeed و NVIDIA خصيصاً لتحسين هذه الحالات الاستخدامية. في Artificial Analysis Speech Arena، تحمل درجة ELO تبلغ حوالي 1,204. بالنسبة للمطورين الذين يبنون واجهات صوتية في الوقت الفعلي حيث كل ملي ثانية مهمة، فإن Cartesia هي الرائدة الواضحة.
8. Inworld Realtime TTS-2

Inworld Realtime TTS-2 Research Preview هو نموذج TTS في الوقت الفعلي الأعلى تصنيفاً على لوحات المتصدرين المستقلة. إنه يتصدر كلاً من Artificial Analysis Realtime TTS Arena بدرجة ELO تبلغ حوالي 1,208 و HuggingFace TTS Arena بدرجة ELO تبلغ 1,578. تحمل هذه التصنيفات المستقلة وزناً كبيراً لأنها تستند إلى اختبارات استماع عمياء بدلاً من ادعاءات البائعين. أظهر النموذج تخفيضاً في التكلفة بنسبة 40% وزيادة بنسبة 4% في الاحتفاظ بالمستخدمين خلال اختبار A/B مع Talkpal AI عبر أكثر من 5 ملايين مستخدم. في دراسة حالة منفصلة، قام Bible Chat بتوسيع نطاق ميزات الصوت بالذكاء الاصطناعي لملايين المستخدمين مع تقليل التكاليف بأكثر من 90% مقارنة بمزود TTS السابق. بالنسبة للمؤسسات التي تعطي الأولوية للأداء المُثبت على ادعاءات التسويق، يقدم نموذج Inworld نتائج مثبتة على نطاق واسع.
9. Kokoro TTS

يقدم Kokoro TTS أسرع سرعة توليد بين الخيارات الصديقة للميزانية، بسعر 0.02 دولار فقط لكل 1000 حرف على منصة fal.ai. وهذا يجعله الخيار المثالي للفرق التي تحتاج إلى توليد صوت سريع بأقل تكلفة ممكنة لكل حرف. على الرغم من نقطة سعره المنخفضة، إلا أنه يقدم جودة مخرجات صلبة مناسبة لبيئات الإنتاج حيث تكون كفاءة التكلفة هي الشاغل الرئيسي. النموذج مناسب بشكل خاص للتطبيقات عالية الحجم مثل السرد الآلي، وأدوات الوصول، وتوطين المحتوى، حيث تفوق السرعة والقدرة على تحمل التكاليف الحاجة إلى جودة صوت مطلقة. بالنسبة للشركات الناشئة والفرق المهتمة بالتكلفة، يوفر Kokoro نقطة دخول سريعة ووظيفية بشكل ملحوظ إلى عالم توليد الصوت بالذكاء الاصطناعي.
10. Maya1 TTS

يكمل Maya1 TTS قائمتنا العشرية بتحقيق سرعات توليد قوية مع التخصص في توصيل الصوت العاطفي. يحصل على درجة جودة كاملة 5/5 ودرجة سرعة 4/5، بسعر 15 رصيداً لكل استخدام. المنصة مصممة للمشاريع التي تتطلب تعبيراً عاطفياً دقيقاً في المخرجات الصوتية، مثل سرد الكتب الصوتية، وحوار الشخصيات، والمساعدين الافتراضيين الواعين عاطفياً. إنه يوازن بين التوليد السريع وقدرات النمذجة العاطفية المتطورة التي تفتقر إليها العديد من الأدوات الأسرع. بالنسبة للمبدعين الذين يحتاجون إلى كل من السرعة والقدرة على نقل التحولات العاطفية الدقيقة، يقدم Maya1 حلاً متخصصاً يملأ فجوة مميزة في السوق.
يتميز مشهد توليد الصوت بالذكاء الاصطناعي في عام 2026 بمقايضة واضحة بين السرعة الخام وجودة المخرجات، لكن الفجوة تضيق بسرعة. نماذج مثل MiniMax Speech 2.6 Turbo و Cartesia Sonic 3.5 Turbo تدفع حدود ما هو ممكن بزمن استجابة أقل من 50 مللي ثانية، بينما تثبت منصات مثل Index TTS 2.0 و Inworld Realtime TTS-2 أن الدقة العالية والسرعة القوية يمكن أن تتعايشا. ومع ذلك، فإن الاتجاه الأكثر أهمية هو الانخفاض الهائل في التكلفة. نموذج S2 من Fish Audio بسعر 15 دولاراً لكل مليون حرف و Kokoro TTS بسعر 0.02 دولار لكل 1000 حرف يجعلان توليد الصوت عالي الجودة والسريع في متناول الفرق التي كانت ستُستبعد بسبب السعر قبل عام واحد فقط. مع استمرار نضوج هذه التقنيات، سيصبح الخط الفاصل بين الكلام الاصطناعي والبشري أكثر صعوبة في التمييز، وستظل السرعة العامل الحاسم للتطبيقات في الوقت الفعلي.
Related Posts




1 Comment
Join the discussion and share your thoughts