I 10 Generatori Vocali AI Più Veloci Al Mondo Nel 2026


Table of Contents
La domanda di discorsi sintetici istantanei e dal suono naturale non è mai stata così alta. Dallo streaming live e agli agenti di intelligenza artificiale conversazionali, fino al servizio clienti automatizzato e alla produzione rapida di contenuti, la velocità di generazione del text-to-speech (TTS) è ora un fattore competitivo cruciale. Per creare questa classifica, abbiamo valutato criteri tra cui la velocità di generazione grezza (misurata in millisecondi di latenza), la qualità dell'output (naturalezza, gamma emotiva e chiarezza), l'efficienza dei costi (prezzi per carattere o per credito) e l'idoneità per applicazioni in tempo reale. Abbiamo consultato classifiche indipendenti come l'Artificial Analysis Speech Arena e la HuggingFace TTS Arena, insieme a guide sui prezzi delle API e analisi di esperti del 2026. Il risultato è un elenco di dieci piattaforme che rappresentano lo stato dell'arte nella sintesi vocale rapida.
La Classifica Dei 10 Generatori Vocali AI Più Veloci Del 2026:
1. MiniMax Speech 2.6 Turbo

MiniMax Speech 2.6 Turbo è in cima alla nostra lista perché dà priorità alla velocità sopra ogni altra cosa senza sacrificare completamente la qualità dell'output. Raggiunge una latenza end-to-end inferiore a 250 millisecondi, rendendolo ideale per gli sviluppatori che necessitano di output vocale quasi istantaneo in applicazioni in tempo reale. Il modello supporta più di 40 lingue e offre centinaia di voci integrate. A soli 6 crediti per utilizzo, offre anche un valore eccezionale. La variante Turbo scambia intenzionalmente una piccola quantità di fedeltà audio rispetto alla sua controparte HD in cambio di una generazione significativamente più veloce e un costo computazionale inferiore. Questo lo rende la scelta ideale per pipeline di produzione rapida di contenuti e chatbot interattivi dove ogni millisecondo conta.
2. ElevenLabs TTS Turbo v2.5

ElevenLabs è stato a lungo il punto di riferimento per il realismo vocale, e il modello TTS Turbo v2.5 dimostra che la velocità non deve andare a scapito della qualità. Questa versione offre tempi di risposta inferiori a 300 millisecondi, consentendo uno streaming senza interruzioni per l'AI conversazionale e i contenuti interattivi. Mantiene i caratteristici schemi di respirazione naturale e l'intonazione emotiva di ElevenLabs, anche ad alta velocità. Con un prezzo di $0,05 per 1.000 caratteri sull'API fal.ai, si colloca a un livello premium, ma è progettato per team che richiedono una qualità vocale di livello umano in progetti a rapida esecuzione. Per le applicazioni in cui sia la velocità che il realismo vocale sono irrinunciabili, questo modello rimane un contendente di prim'ordine.
3. VibeVoice 0.5B

VibeVoice 0.5B si guadagna il posto come opzione di miglior valore tra i primi tre. Offre una qualità eccezionale rispetto al suo prezzo, con velocità di generazione elevate e molteplici voci naturali disponibili a soli 6 crediti per utilizzo. L'architettura leggera del modello consente un'inferenza rapida senza richiedere hardware costoso, rendendolo accessibile a creatori indipendenti e piccoli studi. Raggiunge una conversione text-to-speech ad alta velocità mantenendo un output audio dal suono naturale, trovando un equilibrio che molti concorrenti faticano a eguagliare a questo prezzo. Per i creatori che necessitano di risultati affidabili senza prezzi premium, VibeVoice è una scelta eccezionale.
4. Index TTS 2.0

Index TTS 2.0 non è il generatore più veloce in assoluto di questa lista, ma detiene il primato di essere il generatore vocale AI con la migliore valutazione complessiva nel 2026 secondo la valutazione completa di JAI Portal. Ottiene un punteggio perfetto di 5/5 per la qualità, offrendo un discorso realistico ed emotivamente espressivo con capacità avanzate di clonazione vocale e controllo delle emozioni. A 15 crediti per utilizzo e un punteggio di velocità di 4/5, è progettato per lavori di doppiaggio professionale e ambienti di produzione esigenti in cui la fedeltà è più importante della velocità grezza. La piattaforma eccelle nel bilanciare la velocità di generazione con la massima fedeltà di output possibile, rendendolo lo strumento preferito per studi e agenzie.
5. Maya Stream
Maya Stream è specificamente ottimizzato per applicazioni di streaming in tempo reale e raggiunge la rara impresa di ottenere un punteggio perfetto di 5/5 sia in velocità che in qualità simultaneamente. È progettato per creatori di contenuti live che necessitano di generazione vocale immediata senza problemi di latenza durante trasmissioni o sessioni interattive. La piattaforma mantiene una qualità audio da trasmissione anche in condizioni di streaming continuo, una sfida tecnica che molti concorrenti non hanno ancora risolto completamente. A 15 crediti per utilizzo, rappresenta un'opzione premium per professionisti che non possono tollerare alcun ritardo nella loro pipeline di generazione vocale.
6. Fish Audio API (Modello S2)
Il modello S2 di Fish Audio sconvolge il mercato con una combinazione convincente di velocità ed efficienza dei costi. Offre tempi di risposta in streaming inferiori a 300 millisecondi, abbastanza veloci per l'AI conversazionale in tempo reale e i contenuti interattivi. La struttura dei prezzi a tariffa fissa di circa $15 per milione di caratteri semplifica la definizione del budget rispetto ai sistemi basati su crediti e rappresenta un vantaggio di costo drammatico rispetto a concorrenti come ElevenLabs, che addebita circa $165 per milione di caratteri. Il modello S2 è costruito sul motore di inferenza open-weights SGLang, consentendo agli sviluppatori di auto-ospitarlo per il controllo completo della propria infrastruttura. La clonazione vocale richiede solo 15 secondi di audio campione e la piattaforma vanta una libreria di oltre 2 milioni di voci. Per i team che scalano le funzionalità vocali a milioni di utenti, questo prezzo da solo è trasformativo.
7. Cartesia Sonic 3.5 Turbo
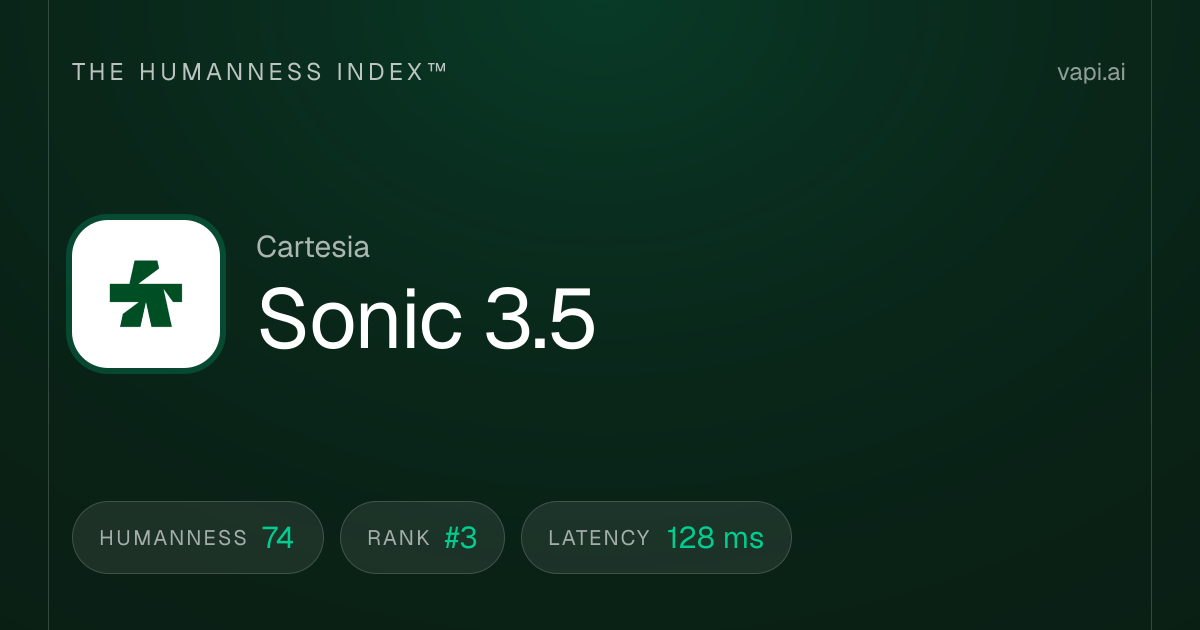
Cartesia Sonic 3.5 Turbo è il modello più veloce in assoluto di questa lista secondo un parametro critico: il tempo al primo byte. Raggiunge circa 40 millisecondi di latenza utilizzando State Space Models (SSM) invece dei transformer utilizzati dalla maggior parte dei concorrenti. Questo tempo di risposta inferiore a 50 millisecondi fa una differenza percepibile nelle applicazioni critiche per la latenza come i sistemi telefonici, gli agenti di servizio clienti live e le esperienze interattive in cui anche 200 millisecondi contro 40 millisecondi sembrano lenti. L'azienda ha raccolto 100 milioni di dollari in finanziamenti guidati da Kleiner Perkins, Index Ventures, Lightspeed e NVIDIA specificamente per ottimizzare questi casi d'uso. Nell'Artificial Analysis Speech Arena, detiene un punteggio ELO di circa 1.204. Per gli sviluppatori che costruiscono interfacce vocali in tempo reale in cui ogni millisecondo conta, Cartesia è il leader indiscusso.
8. Inworld Realtime TTS-2

Inworld Realtime TTS-2 Research Preview è il modello TTS in tempo reale con la migliore valutazione nelle classifiche indipendenti. Guida sia l'Artificial Analysis Realtime TTS Arena con un ELO di circa 1.208 che la HuggingFace TTS Arena con un ELO di 1.578. Queste classifiche indipendenti hanno un peso significativo perché si basano su test di ascolto alla cieca piuttosto che su dichiarazioni dei venditori. Il modello ha dimostrato una riduzione dei costi del 40% e un aumento del 4% nella fidelizzazione degli utenti durante i test A/B con Talkpal AI su oltre 5 milioni di utenti. In un caso di studio separato, Bible Chat ha scalato le funzionalità vocali AI a milioni di utenti riducendo i costi di oltre il 90% rispetto al loro precedente fornitore TTS. Per le organizzazioni che danno priorità alle prestazioni verificate rispetto alle affermazioni di marketing, il modello di Inworld offre risultati comprovati su larga scala.
9. Kokoro TTS

Kokoro TTS offre la velocità di generazione più rapida tra le opzioni economiche, con un prezzo di soli $0,02 per 1.000 caratteri sulla piattaforma fal.ai. Questo lo rende la scelta ideale per i team che necessitano di generazione vocale rapida al costo per carattere più basso possibile. Nonostante il suo prezzo basso, offre una qualità di output solida adatta ad ambienti di produzione in cui l'efficienza dei costi è la preoccupazione principale. Il modello è particolarmente adatto per applicazioni ad alto volume come la narrazione automatizzata, gli strumenti di accessibilità e la localizzazione di contenuti, dove velocità e convenienza superano la necessità di una qualità vocale assoluta. Per startup e team attenti ai costi, Kokoro fornisce un punto di ingresso notevolmente veloce e funzionale nella generazione vocale AI.
10. Maya1 TTS

Maya1 TTS completa la nostra top ten raggiungendo forti velocità di generazione specializzandosi nella consegna vocale emotiva. Ottiene un punteggio perfetto di 5/5 per la qualità e un punteggio di 4/5 per la velocità, con un prezzo di 15 crediti per utilizzo. La piattaforma è progettata per progetti che richiedono un'espressione emotiva sfumata nell'output vocale, come la narrazione di audiolibri, il dialogo dei personaggi e gli assistenti virtuali emotivamente consapevoli. Bilancia la generazione rapida con sofisticate capacità di modellazione emotiva che molti strumenti più veloci non hanno. Per i creatori che necessitano sia di velocità che della capacità di trasmettere sottili cambiamenti emotivi, Maya1 offre una soluzione specializzata che occupa una nicchia distinta nel mercato.
Il panorama della generazione vocale AI nel 2026 è definito da un chiaro compromesso tra velocità grezza e qualità dell'output, ma il divario si sta rapidamente riducendo. Modelli come MiniMax Speech 2.6 Turbo e Cartesia Sonic 3.5 Turbo stanno spingendo i confini di ciò che è possibile con una latenza inferiore a 50 millisecondi, mentre piattaforme come Index TTS 2.0 e Inworld Realtime TTS-2 dimostrano che alta fedeltà e buona velocità possono coesistere. La tendenza più significativa, tuttavia, è la drastica riduzione dei costi. Il modello S2 di Fish Audio a $15 per milione di caratteri e Kokoro TTS a $0,02 per 1.000 caratteri stanno rendendo la generazione vocale rapida e di alta qualità accessibile a team che sarebbero stati esclusi solo un anno fa. Con la continua maturazione di queste tecnologie, il confine tra discorso sintetico e umano diventerà sempre più difficile da distinguere, e la velocità rimarrà il fattore decisivo per le applicazioni in tempo reale.
Related Posts




1 Comment
Join the discussion and share your thoughts